
อยากเป็น DE ควรเริ่มต้นเรียนอะไร?
เริ่มทำงาน DE แล้วควรรู้อะไรเพิ่มบ้าง?
ในสายงาน DE จะเติบโตยังไงได้บ้าง?
คำถามเหล่านี้เป็นคำถามที่เรามักจะเห็นบ่อยๆจากคนที่อยากศึกษาสายงาน Data Engineer (DE) หรือเปลี่ยนมาทำงาน DE รวมไปถึงคนที่เข้ามาในสายงาน DE ได้แล้วก็ยังเกิดคำถามว่าแล้วเราจะพัฒนาตัวเองในสายงานนี้ต่อไปอย่างไรหรือเติบโตได้อย่างไรบ้าง
บทความนี้จึงอยากจะพาทุกคนที่สนใจงานทางด้าน DE มารู้จัก Skill sets ที่เกี่ยวข้องตั้งแต่ Foundation สำหรับผู้เริ่มต้นจนไปถึงภาพใหญ่ระดับ Management กันค่ะ
ต้องขอบอกก่อนว่าตัวผู้เขียนเองไม่ได้มีความรู้ลึกในทุกๆ Skill/Area ที่เขียนถึงในบทความนี้ แต่พอมีความรู้กว้างๆและรู้ว่าทำไมต้องรู้สิ่งนี้เพื่ออะไรในสายงาน DE ดังนั้นในแต่ละ Skill/Area ผู้เขียนจะเริ่มด้วยคำว่า Why? : ทำไม DE ควรรู้สิ่งนี้ เพื่ออะไร
Disclaimer : บทความนี้เขียนจากประสบการณ์ส่วนตัวของผู้เขียนที่เป็น Data Engineer ในระยะเวลา ~4 ปี ซึ่งอาจจะมีข้อผิดพลาดและแต่ละคนอาจมีมุมมองที่แตกต่างกัน ผู้เขียนเปิดรับ feedback เพื่อให้บทความนี้มีความถูกต้องและเป็นประโยชน์กับผู้อ่านมากที่สุดค่ะ
- Intro : Expectation ที่เปลี่ยนไปของ Data Engineer
- Fundamental Skills
- Expected skills from DE these days
- Management Level Skills
Intro : Expectation ที่เปลี่ยนไปของ Data Engineer
ก่อนที่จะลงไปอธิบาย Skill อยากให้ทุกคนเห็นภาพรวมของ DE ในปัจจุบันก่อนค่ะ จะได้เข้าใจมากขึ้นว่าทำไม Skill ต่างๆถึงจำเป็นในสายงาน DE
เมื่อ 6–7 ปีที่แล้ว ในประเทศไทยเริ่มมองหา Data Engineer มาทำ ETL, Data Pipeline, สร้าง Data Lake ในบริษัทเพื่อให้ Data Scientist หรือ Data Analyst นำ data ไปใช้ต่อได้ง่ายขึ้น เลยทำให้ Expectation ต่อ DE ในตอนนั้นจำกัดอยู่ที่การทำ Data Pipeline และ Transform หรือ Clean ให้เหมาะกับการใช้งานต่อ โดยได้รับความช่วยเหลือจาก Platform หรือ Tech team ในการสร้าง Infrastructure ให้สำหรับการทำ Data
ต่อมาประมาณ 4–5 ปีที่แล้ว Data stack มีการพัฒนาอย่างรวดเร็วเพื่อให้ตอบโจทย์ในการทำ Data มากยิ่งขึ้น Technology ในสาย Data เริ่มมีความ specific มากขึ้นและแตกต่างจาก Tech stack ที่ใช้ในการทำ Software ทั่วไป ทำให้ Expectation ที่มีต่อ DE โดยเฉพาะระดับ Senior เริ่มมีเรื่องของการทำ Data Platform และ Infrastructure มากขึ้น บริษัทใหญ่ๆเริ่มมีตำแหน่งแยกออกไปเป็น Data Platform Engineer หรือ Data Architect แต่บริษัทเล็กๆที่เพิ่งเริ่มทำ Data ก็ยังใช้ชื่อตำแหน่ง Senior DE อยู่ ในขณะเดียวกัน การทำ Data model ให้พร้อมใช้งานนั้น DE ต้องมีความรู้ของ Business domain ด้วย ซึ่งทำให้การ deliver ค่อนข้างช้า จึงเกิด tool ชื่อ dbt ที่ทำให้คนที่ไม่ได้ลงลึกด้าน DE สามารถสร้าง Data pipeline และ data model ได้ง่ายขึ้น และมีตำแหน่งชื่อ Analytics Engineer เกิดขึ้นมา
จนมาถึงปัจจุบันหลายๆบริษัทอยากเป็น Data-driven company และเริ่มทำ Data Strategy มากขึ้น และเล็งเห็นว่าส่วนสำคัญที่สุดของการทำ Data คือการสร้าง Foundation หรือ Platform การเก็บ Data ให้ดี รวมไปถึงการมี Standard และ Process ที่เกี่ยวข้องกับ Data ที่ดีด้วย ซึ่งส่วนนี้จะเกี่ยวกับ Data Management และ Data Governance ทำให้หลายๆบริษัทเริ่มหา Lead/Head ของ DE ที่มีความรู้ทางด้านนี้ด้วย
จะเห็นได้ว่า Expectation ของสายงาน DE ค่อยๆขยับขยายออกไปเรื่อยๆตาม Data Adoption ของบริษัทต่างๆ ถ้าบริษัทใหญ่ที่มี Structure ชัดเจนจะแยกตำแหน่งและ Responsibility ไปเลย เช่น Data Engineer, Data Platform Engineer, Analytics Engineer, Data Governance Officer ทำงานร่วมกันเพื่อขับเคลื่อนการใช้ Data แต่ถ้าบริษัทขนาดเล็กหรือกลางตัวผู้เขียนเองยังเห็นว่าหน้าที่ต่างๆเหล่านี้ส่วนใหญ่จะตกไปอยู่ที่ทีม Data Engineering ค่ะ
จากที่เล่ามาจึงทำให้ขอบเขต Skill ที่จำเป็นสำหรับ DE ค่อนข้างเยอะเลยทีเดียว เพราะไม่ได้จำกัดแค่การทำ ETL ตามที่หลายๆคนเข้าใจอีกต่อไป หากสนใจศึกษา Landscape ทั้งหมดของ DE สามารถอ่านได้จากหนังสือ Fundamentals of Data Engineering ค่ะ
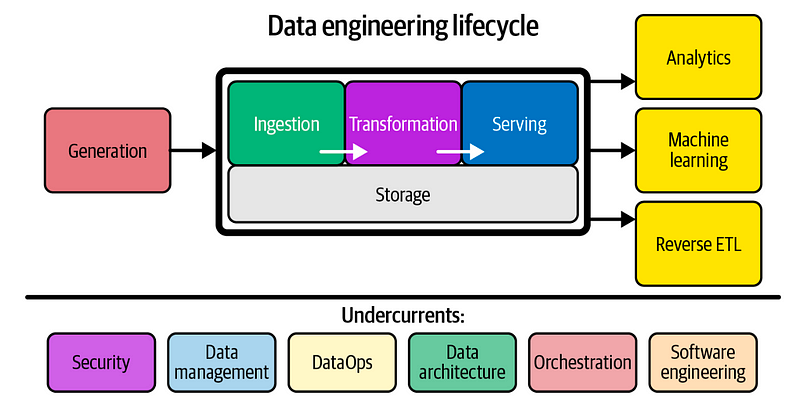
พอเห็นภาพของ DE ในปัจจุบันกันแล้ว มาเริ่มต้นด้วย Fundamental skills ของ DE กันค่ะ
Fundamental Skills
ส่วนนี้จะเป็น Skills พื้นฐานของ DE ที่คิดว่าต้องมีกันทุกคนค่ะ
Data Storage
Why? : ในงาน DE จะเจอกับการเก็บ Data หลากหลายรูปแบบ ความเข้าใจวิธีการเก็บ data แบบต่างๆจะทำให้สามารถดึง data และ transform ได้ถูกต้อง
- Relational DB : Basic สุดสำหรับการเก็บ data ของ web/app services เช่น MySQL หรือ Postgres การดึง data ค่อนข้างง่ายเพราะอยู่ในรูปแบบ table และมี schema ชัดเจน ทาง DE สามารถดึงมา process ในรูปแบบของ dataframe ได้ง่าย ในบริษัทเล็กๆที่เริ่มทำ data ไม่ได้มี data เยอะก็อาจจะเลือกใช้ Relational DB เป็น Data warehouse ในตอนแรก ความรู้เรื่องการทำ index, ออกแบบ primary key, foreign key จะมีส่วนช่วยทำให้ query performance ดีขึ้น
- NoSQL : ถึงแม้ Relational DB จะง่าย แต่ก็มีข้อจำกัดหลายอย่าง จึงทำให้ service เริ่มหันมาใช้ NoSQL มากขึ้น มีความ flexible ในเรื่องของ schema ที่ไม่จำกัดการเก็บ data ในรูปแบบ tabular ทาง DE ก็จะต้องเข้าใจการเก็บ data ที่หลากหลายมากขึ้นและ transform ออกมาในรูปแบบ table ที่ใช้งานง่ายและกำหนด schema ที่ชัดเจน ส่วนใหญ่ที่น่าจะเจอ เช่น MongoDB (Document), Redis (Key-value), Cassandra (Wide-column)
- File : ทุกคนน่าจะคุ้นเคยกับ csv กันดี ส่วนในทาง Big data การเก็บ data ส่วนใหญ่จะเก็บในรูปแบบของ file พวก parquet, avro, orc ซึ่งผ่านการ compression ทำให้มีขนาดเล็ก ประหยัดค่า storage รวมถึงมี metadata ที่บอก schema ของเนื้อ data ด้วย ใครที่ทำงานกับ Spark หรือ Big data framework ก็จะทำงานกับ file พวกนี้เป็นหลัก การออกแบบวิธีการจัดเก็บจะมีเรื่องของการทำ partition/bucket เพื่อให้การ query หรือ join มี performance ที่ดีขึ้น
- Kafka/Message Queue (MQ) : ถ้าได้ทำ streaming pipeline หรือ realtime data ส่วนใหญ่จะดึง data จาก Kafka/MQ (การทำงานของ 2 อย่างนี้ไม่เหมือนกัน) Concept ที่อาจจะได้เจอในโลกของ streaming จะมี Event-driven architecture (เกิด event ที่ service แล้ว service ส่ง data มาใน Kafka/MQ) กับ Change Data Capture หรือ CDC (ดึง change ของ DB จาก binlog หรือ oplog ใน DB แล้วส่งเข้า Kafka) ทาง DE จะเขียน app มา consume data จาก Kafka/MQ แล้ว transform อยู่ในรูปแบบ table สำหรับ monitor report แบบ realtime
Data Processing & Orchestration
Why? : ความเข้าใจการทำงานเชิงลึกของ technology ที่ใช้ในการ process data จะทำให้สามารถใช้งาน technology เหล่านั้นได้อย่างมีประสิทธิภาพโดยใช้ resource/cost ที่มีอยู่อย่างคุ้มค่า เวลาเกิดปัญหาอะไรจะสามารถหา root cause และแก้ปัญหาได้อย่างเหมาะสม
Distributed Computing System
เบื้องหลังการทำงานของ Spark หรือ Tech stack ของ Big data ส่วนใหญ่เรียกว่า Distributed Computing System คือการทำงานหรือ process data จะไม่ได้เกิดขึ้นที่เครื่องเดียว แต่มีเครื่องหลายๆเครื่อง ช่วยกัน process และจะเรียกกลุ่มเครื่องเหล่านั้นว่า Cluster การทำงานเกิดขึ้นในลักษณะของ Master และ Worker โดย Master คุมการทำงานของ Worker แบ่ง data หรืองานออกเป็นส่วนเล็กๆแล้วให้ Worker ช่วยกันทำงาน
ถ้าเข้ามาในโลกของ Big data จะเจอชื่อเรียกหลากหลาย แต่ High level concept ค่อนข้างคล้ายๆกัน เช่น Spark (Driver-Executor), Trino/Presto (Coordinator-Worker), HDFS (NameNode-DataNode)
ต่อไปจะพูดถึงการ Process และทำ Data pipeline ซึ่งจะแบ่งออกเป็น Batch และ Streaming ค่ะ
Batch Pipeline
ทุกบริษัทหรือคนที่เข้ามาทำงานสาย DE น่าจะเริ่มจากจุดนี้ คือเขียน Job/Task ขึ้นมาเพื่อ extract data จาก DB หรือ ingest จาก csv file แล้ว transform และ load เข้า Data lake หรือ Data warehouse ซึ่ง process นี้จะเรียกว่า ETL หรือมีอีกท่าที่นิยมใช้กันคือการ extract แล้ว load ลง Lake/Warehouse ก่อน เสร็จแล้วค่อยมา transform ทีหลังซึ่งจะเรียกว่า ELT ส่วนใหญ่จะทำเป็น schedule รันทุกๆวันหรือทุกชั่วโมง
Technology ที่ใช้ในการทำ ETL/ELT กับ data ขนาดใหญ่ที่เป็นพื้นฐานตอนนี้คือ Spark การเขียน Spark job ให้ transform data ได้ตามที่ต้องการก็เป็นเรื่องหนึ่ง แต่เมื่อมี data มากขึ้น มี Spark job หลายตัว ต้องการความ scalability มากขึ้น และลด runtime ให้น้อยลง จะเจอกับปัญหาการจัดการ resource ใน Spark cluster ตัว Spark เองใช้ memory ในการทำงานเป็นหลัก เบื้องต้นก็จะปรับ driver/executor memory ให้มากพอที่จะไม่เจอ memory error แต่ถ้าได้ลองไปศึกษาเชิงลึกของ Spark จริงๆจะมี concept และ parameter หลายตัวให้ปรับจูนมากมาย เช่น Serialization, Parallelism, Shuffle, Repartition, Disk spill หรือการอ่าน Spark plan ที่ทำให้เห็นจุดที่มีปัญหาได้ ความเข้าใจตรงนี้จะสามารถลดการใช้ memory และลด cost ได้
เพื่อลด overhead ในการปรับจูนเรื่องพวกนี้ Cloud services จะมีบริการประเภท serverless ที่ไม่ต้องใส่ใจกับเรื่องพวกนี้มากนัก แต่การคิด cost เท่าที่เห็นจะคิดเป็น DPU (Data Processing Unit) ซึ่งเมื่อ data ใหญ่ขึ้นก็จะทำให้ cost สูงขึ้นเช่นกัน
Data Orchestration เป็นสิ่งที่มาพร้อมกับการทำ Batch pipeline โดย tool ที่เป็นที่นิยมมากที่สุดคือ Airflow ที่ช่วยการทำ Data pipeline ให้ง่ายและเป็นระเบียบ จัดการ scheduling ทั้งแบบ cron (กำหนดเวลา) และแบบ dependency (trigger เมื่อ job อื่นเสร็จ) สามารถออกแบบ data pipeline แบบ dynamic ได้ รวมไปถึงการส่ง Alert เมื่อ Data pipeline มีปัญหา นอกจาก Airflow ยังมี tools อื่นๆที่อาจจะได้ใช้กัน เช่น Dagster, Mage, Azure Data Factory
ส่วนในการทำ ETL เองก็มี tools สำเร็จรูปที่มาช่วยให้ DE ทำงานง่ายขึ้น ในเรื่องการ extract data จาก source ต่างๆจะมี Airbyte และ Fivetran ที่เรียกตัวเองว่าเป็น Data Integration Tool มี plugin ต่อกับ 3rd party หลายตัวหรือในส่วนของ transform ก็มี dbt ที่ติดตลาดแล้ว มาช่วยให้การ transform data ง่ายขึ้นเพียงแค่เขียน SQL เป็น
Streaming pipeline
ในบางธุรกิจ การทำ daily/hourly report แบบ batch อาจไม่เพียงพอต่อการตัดสินใจหรือ action สำคัญๆ ทาง DE จึงต้องทำ Near-realtime หรือ Realtime data pipeline ขึ้นมา
จากที่กล่าวไปในหัวข้อก่อน ส่วนใหญ่ data จะถูก ingest เข้ามาใน Kafka แล้ว DE จะเขียน app ไปดึง data เพื่อ transform ต่อ โดย framework ทาง streaming ที่เป็นที่นิยมในปัจจุบันมี 2 ตัว
- Spark Structured Streaming : concept ของตัวนี้จะทำงานในลักษณะ microbatch ที่สามารถ fix interval การ process data ได้ เช่น ทุกๆ 5 นาทีหรือ 10 นาที หรือจะให้ run ทุกครั้งหลังจากที่ batch ก่อนหน้านี้จบก็ได้ในกรณีที่ทำไม่ทันตาม interval ที่ตั้งไว้
- Apache Flink : ส่วน Flink จะ support ทั้งแบบ continuous และแบบ microbatch แบบ continuous จะทำงานคล้ายๆ while loop ที่พอมี data เข้ามาเมื่อไหร่ก็ process ทันทีเลย ทำให้ latency ต่ำมากๆ
ในโลกของ streaming จะมี concept ที่ต่างจาก batch ทั้งในเรื่องของตัว app streaming เป็น long-running ที่ hold resources (memory) ไว้ตลอด หรือ concept อื่นๆ เช่น Checkpoint, Late arriving, Watermarks, Stream join, Failure recovery (ห้ามตายไม่งั้นไม่ realtime) ซึ่งมีความซับซ้อนกว่า batch และ cost สูงกว่ามาก
ความแตกต่างของ Spark และ Flink คือการจัดการ concept ที่กล่าวมาข้างต้น แต่ละตัวมีข้อดีและข้อเสียต่างกันตามแต่ละ use cases ค่ะ
Programming & Software Engineer
Why?
- สามารถเลือกใช้ภาษาให้เหมาะสมกับแต่ละ requirement และสามารถเขียน code ที่ optimize resources (memory) ได้
- สามารถเขียน code ในระดับ production-grade และง่ายต่อการ maintain ในระดับทีม
Programming Language
คนที่เข้ามาสาย DE ใหม่ๆมักจะมีคำถามว่าต้องเรียนรู้ภาษาอะไรบ้าง แต่เราขอเก็บมาอธิบายตรงนี้ เพื่อให้ผู้อ่านเข้าใจ technology ของการทำ data ก่อน แล้วจะเข้าใจมากขึ้นว่าทำไมต้องรู้จักและใช้ภาษาเหล่านี้ค่ะ
- Advanced SQL : ขอย้ำว่า “Advanced” ไม่ใช่ SQL ธรรมดา ในบทบาทของ Data analyst/Data science จะเน้นการเขียน SQL เพื่อให้ได้ data ที่ต้องการ แต่ในบทบาทของ DE นอกจากได้ผลลัพธ์แล้ว จะเน้นเขียน SQL ที่ optimized ในเชิง resources และ runtime ด้วย เช่น การเขียน CTE process เฉพาะ data ที่จำเป็นก่อนเพื่อให้ data มีขนาดเล็กสุดแล้วนำไป join หรือการทำ predicate pushdown ที่อ่าน data ให้น้อยที่สุดตั้งแต่ source ที่เป็น file เพื่อลด memory และเวลาอ่าน file ดังนั้นการ optimize query จึงอาจเป็นงานของ DE อย่างหนึ่ง
- Python : ภาษาเบสิคของการทำ data ไม่ว่าจะเป็นการใช้ pandas, numpy มา process dataframe หรือต่อยอดไปที่ PySpark เขียน transform บน Spark รวมไปถึงการเขียน Airflow DAG ที่ใช้ Python เป็นหลัก สาย data ต้องเป็นอยู่แล้ว
- JVM languages (Java/Scala) : ถึงแม้ Python จะมีความง่าย แต่จริงๆแล้วมีข้อเสียอยู่ก็คือ runtime ช้า ต้องอธิบายว่าจริงๆแล้วพวก Big data framework ไม่ว่าจะเป็น Spark หรือ Flink ตัว Native language ที่ใช้พัฒนาจริงๆคือ Scala กับ Java และการจัดการ memory ก็ใช้ JVM หมด เขามี abstract layer สำหรับ Python เพื่อให้คนเข้ามาใช้ง่ายขึ้น ดังนั้นเวลา run job จริงๆ จะมี overhead ในการแปลง Python เป็น Scala/Java อยู่ ทำให้ job รันช้าขึ้น สำหรับ use cases ที่ต้องการ latency ต่ำๆอย่างเช่น realtime ส่วนใหญ่จะใช้ Scala/Java กัน DE เลยมีโอกาสได้แตะภาษาเหล่านี้ด้วย
Software Engineer
จริงๆแล้ว DE = Software Engineer + Data Domain ดังนั้นงาน DE จึงมีการ apply concept ของ software engineer ในการพัฒนา codebase ด้วย ถ้าทำงานคนเดียวอาจจะเริ่มต้นด้วยการเขียน script ง่ายๆ แต่พอทำงานเป็นทีมแล้ว มีส่วนที่ต้องแชร์กัน จะเริ่มทำเป็น Git repo ที่มี ETL/ELT framework หรือ package ที่ทุกคนใช้งานร่วมกัน โดยทีมไม่ต้อง Reinventing the wheel หรือทำงานซ้ำๆกัน ก็อบแปะไปใช้แบบกระจัดกระจาย แต่ทุกคนสามารถ reuse สิ่งที่คนอื่นทำไปแล้วได้ ทำให้การทำ pipeline มีมาตรฐานและ deliver data ได้เร็วขึ้น โดย concept/tools หลักๆที่นำมาใช้คือ
- Object Orient Programming (OOP) : การทำ framework จะแบ่ง code ออกเป็น domain ต่างๆ แล้วเขียนเป็น class มี function ที่ทำงานเฉพาะ domain นั้นๆ เช่น transformer, source connector, data writer การใช้ OOP มาช่วยจะลดความ dependency และสามารถ maintain ได้ง่ายขึ้น
- Test Driven Development (TDD) : ส่วนที่ DE นำมาใช้เยอะคือการเขียน unit test เช่น เวลาเขียน transformer ตัวหนึ่ง จะเขียน unit test ว่าให้ผลลัพธ์ตามที่คาดหวังหรือไม่ unit test จะช่วยลดเวลาในการ test ว่า code ทำงานถูกต้องโดยไม่ต้องเสียเวลารอ spark job รันจบทุกครั้ง หรือถ้ามีการเปลี่ยนแปลงใดๆเกิดขึ้น unit test จะช่วยเช็คว่าทุกอย่างยังทำงานได้เหมือนเดิม นอกจากนั้นจะมีการทำ integration test เพื่อทดสอบว่า pipeline รันได้ถูกต้องทั้ง flow
- CI/CD : เมื่อเขียน framework เสร็จแล้ว จะมีการทำเป็น package หรือ deploy เพื่อไปใช้งาน ถ้าต้องทำบ่อยๆคงไม่มานั่งกดมือเองทุกครั้ง CI/CD จะช่วยมา automate สิ่งนี้ให้ ถ้าใช้พวก Git จะมี Github actions, Gitlab CI ที่สามารถเขียน workflow กำหนดได้ว่าเมื่อ push แต่ละครั้งต้องทำอะไรบ้าง
- Docker/Kubernetes : ในการเขียนหรือ test code ส่วนใหญ่จะทำในเครื่อง local ก่อน แต่เราต้องมั่นใจว่าทุกคนในทีมกำลัง dev ใน environment เดียวกันและเหมือนกับบน production ซึ่งจะใช้ docker มาช่วยในส่วนนี้ โดย setup ทุกอย่างให้เหมือนกับ production มากที่สุด ทั้งตัว python, spark, lib version และการเชื่อมต่อกับ Airflow หรือ component อื่นๆ ส่วนถ้าใครมีโอกาสเขียน data service เองหรือ deploy data tools ต่างๆเอง ก็มีโอกาสได้ใช้ Kubernetes ในการ deploy
Data Modeling
Why? : สามารถออกแบบ table ที่ตอบโจทย์ requirement ของ analyst และ business ได้
พอได้ data มาจาก source แล้วตรงนี้จะเป็นส่วนที่ออกแบบ table ให้เหมาะสมกับการใช้งานของฝั่ง analytics ค่ะ
Dimensional Modeling
ส่วนใหญ่ concept ของการออกแบบ table ใน Data warehouse จะใช้ Kimball Methodology แบ่งประเภท table เป็น fact และ dimension แล้วออกแบบ structure ภายใน data warehouse เป็น Star schema หรือ Snowflake schema ขึ้นอยู่กับลักษณะของ data และการใช้งาน
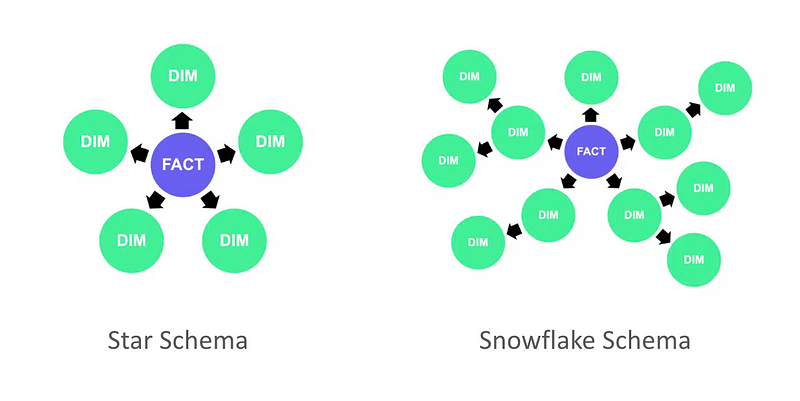
ข้อดีของการแบ่ง table แบบนี้คือ data ค่อนข้างเป็น structure แบ่งเป็นหมวดหมู่ หาง่าย แต่ข้อเสียคือเวลาทำ report หรือ analytics จริงๆ ผู้ใช้ต้อง join table เยอะทำให้ query มีความซับซ้อน รันนาน และไปโหลดที่ data platform
เลยมี concept เพิ่มมาช่วยแก้ปัญหานี้เรียกว่า Data Cube ที่รวมทั้ง fact และ dimension ใน table เดียวกันไปเลยเพื่อให้ตอบโจทย์แต่ละ use case ของ report ต่างๆ โดยการ implement ส่วนใหญ่ก็จะเอา fact และ dimension table ใน warehouse มา join กันออกมาเป็น cube แล้วใส่เข้าไปใน data mart
Tech & Business Understanding
DE เป็นเหมือนคนกลางระหว่างทีม tech กับ business ในเรื่อง data ทาง analyst หรือ business จะเข้ามาหา DE ด้วย requirement เช่น อยากทำ report แบบนี้ อยากดู metric นี้ ขอ data หน่อย DE จะต้องเข้าใจ use case ของแต่ละ requirement ซึ่งอาจรวมไปถึง domain knowledge หรือ process ของทาง business ด้วย จากนั้นต้องไปตามหากับทีม tech ว่า data source เก็บอยู่ที่ไหน ความหมายของแต่ละ column/field ตรงกับ requirement ไหม บางทีก็ต้องเข้าใจว่า service ของ tech ทำงานยังไง create/update data ตอนไหนบ้าง เพื่อที่จะได้ทำ data model ได้ถูกต้องตาม requirement
อย่างที่กล่าวไปใน intro ว่าตรงส่วนนี้อาจจะมี Analytics Engineer (AE) เข้ามาช่วย leverage ส่วนของ business domain แทน เพราะกว่า DE จะ map tech กับ business ได้ก็ใช้เวลาพอสมควร ทำให้บางที deliver data ช้า การทำงานอาจจะเปลี่ยนเป็น DE เน้นไปทางฝั่ง tech มากขึ้น AE ไปคุยกับ business แทน แล้ว DE กับ AE ทำงานร่วมกัน
จบตรงนี้คิดว่า DE ทุกคนสามารถทำ data pipeline และออกแบบ table ให้ตอบโจทย์ผู้ใช้งานได้แล้ว ส่วนต่อไปจะเป็นส่วนที่เริ่มมีความสำคัญมากขึ้นสำหรับสายงาน DE ในปัจจุบันค่ะ
Expected skills from DE these days
ส่วนนี้จะเป็น skills และ knowledge ที่เริ่มมีความสำคัญและต้องการจาก DE มากขึ้นในปัจจุบันค่ะ
Data Platform & Architecture
Why?
- สามารถออกแบบ Data Platform Architecture ให้เหมาะสมกับการใช้ data ในบริษัทได้
- สามารถสร้างและดูแล Data Platform ให้ scalability และ reliability โดยใช้ resource/cost ให้คุ้มค่าที่สุด
ในระดับ Senior ขึ้นไป DE มีโอกาสได้ออกแบบ สร้าง หรือดูแล data platform ในบริษัทมากขึ้น อาจมีโอกาสได้ build from scratch เลยถ้าบริษัทกำลังรื้อหรือทำ data strategy ใหม่ รวมไปถึงการเลือก technology ที่เหมาะสมสำหรับ platform ในตำแหน่ง DE จึงมีความเป็น devops ด้วยส่วนหนึ่ง
Breadth and Depth of Tech Stack on Cloud
บริษัทส่วนใหญ่ในปัจจุบันใช้ cloud กันหมดแล้ว (น้อยมากที่ยัง on-premise) เลยคิดว่าศึกษาพวก data services บน cloud ไปเลยดีกว่า เจ้าหลักๆมี AWS, GCP, Azure ซึ่งแต่ละเจ้ามีชื่อเรียก service, การ setup และการใช้งานต่างกัน ขึ้นกับว่าแต่ละบริษัทใช้ cloud เจ้าไหน ก็ต้องไปศึกษา services และเลือกใช้ให้เหมาะสม จึงเป็นส่วน breadth ที่อาจจะต้อง explore services หลายๆตัวก่อน
พอตัดสินใจสร้างและใช้งานแล้วจะเป็นส่วน maintain ที่อาจจะเจอปัญหาหลายๆอย่างใน platform ตรงนี้อาจจะต้อง depth ลงไปศึกษาการทำงานของแต่ละ service เพื่อหาต้นตอปัญหาและแก้ไขให้ platform มีความ reliability
ส่วน data service อื่นๆที่มาแรงมากๆในตอนนี้ คือ Databricks และ Snowflake เรียกได้ว่าแย่งตลาดกันดุเดือดมาก มี blog เปรียบเทียบมากมาย ทั้ง 2 ตัวสามารถ deploy on top cloud ทั้ง 3 เจ้าได้และทำตัวเป็นเหมือน one stop service ของการทำ data และมี UI ที่ friendly กับผู้ใช้งาน
Cloud Network & Security
ส่วนของ architecture เมื่อเลือกและสร้าง service แล้ว จะต้อง setup ให้ service ต่างๆบน cloud สามารถติดต่อหรือส่ง data ผ่านกันได้ รวมไปถึงการกำหนด security ให้แต่ละ service ติดต่อกันหรือให้ผู้ใช้เข้าถึงได้เฉพาะส่วนที่จำเป็นเท่านั้น ตรงนี้ต้องใช้ความรู้เรื่อง Network & Security หลักๆก็จะมีเรื่อง VPC, Subnet, Route table, Load balancer, Security group, IAM
Infrastructure as a Code (IaC)
ถ้าเป็นมือใหม่หัดใช้ cloud ก็จะสร้าง service ต่างๆบน cloud console แบบกด ใส่ config แบบ manual แต่ในการทำงานจริงจะทำงานโดยแบ่งเป็น environment เช่น dev, qa, prod ถ้ามีหลาย service แล้วมากดมือทุกอันจะทำให้เสียเวลาและเกิด human error ได้ง่าย
ปัจจุบันเลยใช้ IaC มาทำ automate ในการสร้าง service ต่างๆ โดยเก็บ service config และ network config ทุกอย่างไว้ใน code แล้วเปลี่ยน variable สำหรับ environment ต่างๆ ทำให้ง่ายต่อการ deploy, scale และ maintain ส่วน tool ที่ใช้กันเยอะคือ Terraform ซึ่ง support cloud หลักๆทั้ง 3 เจ้าเลย
Monitoring & Logging
เพื่อเพิ่มความมั่นใจว่า platform จะไม่มี downtime จะมีการติด monitoring เพื่อดู cluster status และ resource เช่น cpu, memory, disk utilization ว่ายังอยู่ดี ไม่ได้ใช้เกินค่าที่กำหนดไว้ ถ้าเกิดมี node down หรือใช้ resource เกินกว่าที่กำหนด จะทำการส่ง alert ให้ DE ไปตรวจสอบดูว่าเกิดอะไรขึ้น มีการใช้งานผิดปกติหรือไม่ หรือลงไปดูที่ log ว่าสาเหตุที่แท้จริงเป็นอะไร จะได้แก้ปัญหาได้ถูกจุด
tool ที่มาช่วยทำ monitoring จะมี Prometheus เป็น time-series database ใช้เก็บ metric ต่างๆและ Grafana เป็น visualization tool ที่ดึง metric จาก Prometheus มาแสดงและทำ alert ได้
ส่วนการทำ logging ส่วนใหญ่จะใช้ ELK stack ที่ดูด log จาก platform ไปลงที่ Elasticsearch แล้ว query ผ่าน Kibana ดูสิ่งที่เกิดขึ้นในช่วงเวลาที่มีความผิดปกติ
Data Quality
Why? : deliver data ที่มีคุณภาพให้กับผู้ใช้ ผู้ใช้จะได้มีความเชื่อมั่นและสามารถนำ data ไปใช้ในการตัดสินใจได้อย่างถูกต้อง
ทุกคนเคยเห็นมีมนี้กันไหมคะ
จริงๆเป็นหน้าที่ของ DE ที่ควรทำให้ data มีความถูกต้องหรือสร้าง Single Source of Truth (SSOT) ให้ผู้ใช้ เพื่อลดเวลาที่ผู้ใช้จะต้องมา clean หรือ validate เอง เรื่องการตรวจสอบ Data Quality จึงถูกนำมา implement ใน pipeline เลย ซึ่งจะมีแกนตรวจสอบตามภาพด้านล่าง

โดยรวมคือจะตรวสอบว่า data ที่ทำให้ผู้ใช้มีความถูกต้อง สมบูรณ์ครบถ้วน ไม่มี data ซ้ำกันหรือหายไป อยู่ใน format ที่ถูกต้องตาม standard ที่กำหนด (เช่น เบอร์โทร) และมีการ update ตามเวลาที่กำหนด (เช่น table นี้ควร update ก่อนตี 4)
tool ที่มาช่วยการเช็ค data quality มี great expectation, soda, deequ หรือใครใช้ dbt ก็จะมี dbt-test โดย tool เหล่านี้จะมี built-in function ที่นำมาใช้ validate data จาก pipeline ได้เลย
Data Observability
Why? : DE จะต้องคอย monitor คุณภาพและสามารถ detect ได้ถ้า data ที่ใช้ทั่วบริษัทมีปัญหา DE ควรรับรู้ปัญหาได้ก่อนและรีบเข้าไปแก้ไขก่อนที่ผู้ใช้จะนำไปใช้งานแบบผิดๆ
การทำ Data Observability คือการ monitor data health ที่ใช้ทั้งบริษัท สามารถ detect ความไม่ปกติที่เกิดขึ้นและรีบเข้าไปแก้ไข DE จะต้องมีความ proactive ต่อ data incident/issue ที่เกิดขึ้น แกนหลักๆที่ monitor ตามภาพด้านล่างค่ะ
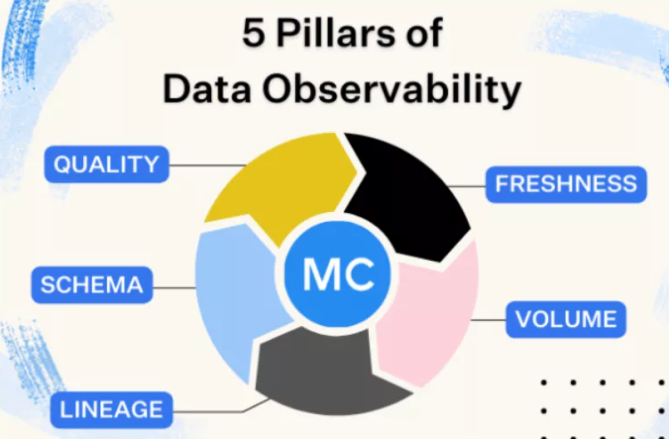
- Freshness : เช็คว่าในระบบไม่มี stale data หรือ data ที่ไม่อัพเดต เพราะจะมีผลต่อการตัดสินใจทางธุรกิจในปัจจุบัน
- Quality : อันนี้จะเกี่ยวข้องกับหัวข้อที่แล้ว พอมีการ check quality แล้ว ถ้าเกิดว่าไม่ตรงตาม quality ที่กำหนดไว้ DE ต้อง detect ได้และรีบเข้าไปหาว่าทำไมและแก้ไขต่อไป
- Volume : เป็นการเช็ค data completeness โดยอ้อมอย่างหนึ่ง เช่น ปกติทุกวันมี data 10M row แต่วันหนึ่งเหลือแค่ 500k row แปลว่าต้องมีอะไรผิดปกติแน่
- Schema : การเปลี่ยน schema เกิดขึ้นได้ตลอดเวลา ซึ่งจะกระทบทั้งกับ pipeline และ query ที่ผู้ใช้งานเขียน จึงต้องคอย monitor จัดการหรือแจ้งให้ผู้ใช้ทราบเมื่อมีการเปลี่ยนแปลงเกิดขึ้น
- Lineage : เป็นการดูว่า data ของทั้งบริษัทไหลไปที่ไหนบ้าง ถ้าทำดีๆจะดูได้ตั้งแต่ data source ที่เป็น web/app db ไปจนถึง dashboard ของผู้ใช้งานเลย เมื่อมีการเปลี่ยนแปลงหรือ data issue เกิดขึ้น จะรู้ได้ว่าเกิดที่ไหนและกระทบกับ downstream table หรือผู้ใช้งานกลุ่มไหนบ้าง เบื้องต้นอาจจะดูในระดับ table แต่ในปัจจุบันมี tool หลายตัวที่สามารถดูในระดับ column ได้แล้ว ทำให้ scope ผลกระทบได้แม่นยำมากขึ้น
tool ที่มาช่วยทำตรงนี้มีหลายตัวแต่ส่วนใหญ่จะเสียเงิน เช่น Monte Carlo แต่ก็มี open-source ที่ชื่อ DataHub ที่คนนิยมใช้กันเยอะและมีการพัฒนาอยู่เรื่อยๆจนคนใช้อัพเดตตามไม่ทัน
DataOps
Why? : DE สามารถ deliver data value ไปสู่ business value ได้อย่างรวดเร็วโดยยังคงคุณภาพได้
DataOps เป็นการออกแบบระบบและ process เพื่อทำให้สามารถ deliver data ได้อย่างรวดเร็วและถูกต้อง รวมไปถึง monitor และ maintain ให้ data ที่ถูก deliver ออกไปแล้วยังคงมีคุณภาพด้วย ส่วนนี้จะเป็นการทำงานร่วมกันระหว่าง DE และทีมอื่นๆที่เกี่ยวข้องทั้ง dev, business, product เพื่อทำลาย silo การทำ data ให้ business ได้ value จาก data เร็วที่สุด
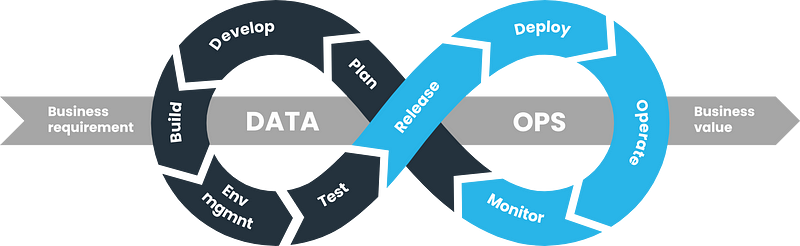
ในส่วนของ DE จะมีการใช้ concept ต่างๆที่อธิบายไปก่อนหน้านี้มาใช้ ไม่ว่าจะเป็น CI/CD, Testing, Monitoring, Data quality, Data observability โดยจะพยายามทำทุกอย่างให้ automate ทั้งหมดเพื่อความรวดเร็วในการ deliver และการ fix issue ต่างๆที่เกิดขึ้น
DataOps จะเน้นไปที่การ automated process เป็นหลักโดยไม่ขึ้นกับ tool และแต่ละบริษัทก็อาจจะมี process ที่แตกต่างกันไปขึ้นกับบริบทของแต่ละบริษัท
จนถึงตรงนี้จะเห็นว่างาน DE จะไม่ได้มีแต่ technical เพียงอย่างเดียว แต่เริ่มมีเรื่องของ process และการ manage data ทั้งบริษัทด้วย การทำให้ data มี value กับบริษัทจะเป็นการทำงานร่วมกันกับหลายๆฝ่าย ต่อไปก็จะเป็น high-level skill มากขึ้นค่ะ
Management Level Skills
ส่วนนี้จะไม่มีความ technical เลย แต่เป็นความรู้ทางด้าน data ในภาพใหญ่ขึ้นที่ Lead/Head DE มีโอกาสเจอ เป็นการทำงานร่วมกับ C-suite/Executive/Manager ทีมอื่นเพื่อกำหนด framework หรือทิศทางการทำ data ภายในบริษัท ซึ่งมีผลต่อการ implement หัวข้อต่างๆที่กล่าวไปแล้วข้างต้น
ต้องขอออกตัวก่อนว่าผู้เขียนเองไม่ได้มีความรู้ลึกในหัวข้อนี้มากนัก เป็นเรื่องที่กำลังศึกษาและพยายามทำค่ะ
Data Governance
Why? : กำหนดกระบวนการและแนวทางในการจัดเก็บและการใช้ dataให้มีมาตรฐานที่ผู้ใช้สามารถใช้งานได้ง่ายและเกิดประโยชน์สูงสุด โดยคำนึงถึงความปลอดภัยด้วย
ส่วนนี้จะเป็นการกำหนด policy, process และ guideline ในการจัดเก็บ การใช้ และการเข้าถึง data ในบริษัทให้มีมาตรฐานและให้ทุกคนปฏิบัติตามร่วมกัน โดยมีแกนหลักๆที่ต้องกำหนดร่วมกันดังนี้
- Data standardization : กำหนดทิศทางในการเก็บ data ทั้งบริษัทให้ไปในทิศทางเดียว ทำให้มี data consistency กันทั้งระบบตั้งแต่ Web/App, Data lake, Data warehouse รวมไปถึงการกำหนด business glossary เพื่อให้ผู้ใช้งานมีความเข้าใจที่ตรงกัน
- Data quality : กำหนดการวัดคุณภาพของ data ตรงนี้จะเกี่ยวข้องกับส่วนที่กล่าวไปข้างต้นว่าจะวัด quality อย่างไร และมีตัวชี้วัดอะไรบ้าง
- Data security/privacy : กำหนดสิทธิการเข้าถึง data เพื่อกันการรั่วไหล กระบวนการเก็บหรือลบ การจัดการ sensitive data หรือ PII
- Compliance : ปกติจะอิงจาก PDPA (ต่างประเทศ GDPR) หรือบางบริษัทอาจจะถูกกำกับด้วยหน่วยงานอื่น เช่น ธนาคารจะถูกกำกับด้วย BOT อีกที
ผลลัพธ์ที่ได้จาก Data governance คือ blueprint หรือ document ที่กำหนดกฎและกระบวนการในการทำ data เพื่อใช้ในหัวข้อถัดไป
Data Management
Why? : ทำสิ่งที่กำหนดจาก Data governance ให้เกิดขึ้นได้จริงในทุกๆส่วนที่เกี่ยวข้องกับ data
Data governance จะจบแค่ document ส่วน Data management จะเป็นส่วน execution หรือ implementation ให้เกิดขึ้นจริง ซึ่งจริงๆแล้วคือหัวข้อที่กล่าวไปใน section ก่อนหน้านี้ทั้งหมด พอเอามายำรวมกันก็จะกลายเป็นการทำ Data management ให้สอดคล้องกับ policy ที่กำหนด ตั้งแต่
- การเลือก technology
- การออกแบบ data architecture และการสร้าง data platform
- การสร้าง ETL/ELT pipeline
- การทำ Data modeling และการจัดการ Master data
- การตรวจสอบ Data quality
- การทำ Data incident management
- การออกแบบ Permission การเข้าถึงของผู้ใช้ในบริษัท
- การส่ง data ออกไปยัง 3rd party platform (e.g. Marketing tools)
ตอนนี้ในต่างประเทศเริ่มทำ Computational governane กัน คือการเอา policy หรือ process ที่กำหนดมาใส่ลงใน code ตั้งแต่ระดับ data architecture และ pipeline เพื่อลด manual process ที่อาจะทำให้มีเคสหลุดได้ง่าย ระบบจะมีความ strict มากขึ้นแต่ก็มี quality ที่ดีขึ้นและปลอดภัยมากข้น
ในชีวิตจริงเราทำ Data governance ก่อน Data management ไหม ก็ตอบเลยว่าไม่เคยค่ะ 555 ปกติบริษัทอยากรีบใช้ data ก็จะทำไปก่อนเลยโดยไม่มีการกำกับใดๆทั้งสิ้น แต่พอถึงจุดหนึ่งที่การใช้ data เริ่มเยอะ มี quality ไม่ดี หรือบริษัทเริ่ม concern เรื่อง security ก็จะมาเริ่มทำ Data governance กัน สุดท้ายส่วนของ Data management ก็อาจจะต้องปรับเปลี่ยนให้สอดคล้องกับ Data governance ที่เกิดขึ้นมาทีหลังค่ะ (แต่มันจะดีกว่ามากนะถ้าเริ่มทำ Data governance กันก่อน)
Data Strategy
Why? : ร่วมออกแบบ Data strategy ให้สอดคล้องกับ Business strategy และ DE สามารถทำ Data management ให้สอดคล้องกับ Data strategy นั้นได้
คิดว่าหัวข้อนี้เป็นร่มใหญ่สุดของการทำ data ทั้งบริษัทแล้ว เป็น long-term plan/roadmap ที่เกี่ยวข้องกับคน, ทีม, กระบวนการ, technology ที่จะนำ data มาใช้ในการตัดสินใจสำคัญๆหรือใช้ในการพัฒนา process ต่างๆให้ตอบโจทย์กับ Business goals ที่บริษัทวางเอาไว้
การทำ Data strategy มีหลายขั้นตอนและเกี่ยวข้องกับหลายฝ่าย แต่จะขออธิบายคร่าวๆตรงส่วนเฉพาะที่เกี่ยวกับ DE ค่ะ
- Alignment with business objectives : ต้องทำความเข้าใจให้ชัดเจนก่อนว่า goals ของบริษัทคืออะไร Metric/KPI ที่อยากจะวัดคืออะไร แล้วมาดูว่า data ไหนที่จำเป็นในการ drive ธุรกิจให้ไปถึง goal นั้น หรือมีโอกาสที่จะใช้ data ที่มีอยู่แล้วมาช่วยได้ไหม
- Gap evaluation : พอรู้ data ที่ต้องการแล้ว DE ต้องมาสำรวจว่ามี data นั้นอยู่ในระบบหรือยัง ถ้าไม่มีจะสามารถไปหาเพิ่มได้จากที่ไหน หรืออาจจะต้องเก็บเพิ่มหรือไม่
- Data architecture & Technology : ออกแบบ data architecture และเลือก technology ที่ตอบโจทย์กับ business goal หรือถ้ามีอยู่แล้วอาจจะต้อง evaluate ว่าสิ่งที่มีอยู่ตอบโจทย์หรือไม่ ถ้าไม่ DE ต้องทำอะไรเพิ่มบ้าง
- Data governance : ตามที่กล่าวไปข้างต้น Data governance เป็นส่วนหนึ่งของการทำ Data strategy เหมือนกัน
- Data Strategy Roadmap : จนถึงขั้นตอนนี้ ทุกฝ่ายจะมาแตก action, ทำ timeline และ prioritize ส่วนที่ต้องทำกัน
- Data management solution : ต่อจากนี้ DE ก็ต้องไป implement ทุกอย่างและ deliver data ให้ทีมอื่นๆไปใช้งานต่อเพื่อให้บรรลุเป้าหมาย
จบแล้วค่ะ Skill sets ตั้งแต่มือใหม่ไปจนถึงระดับ Management จะเห็นได้ว่าเส้นทางการเป็น DE นั้นไม่ง่ายเลย เมื่อบริษัทมีการใช้ data เยอะขึ้น ตำแหน่ง DE เป็นเหมือนคนสร้าง foundation ให้กับการทำ data ของบริษัททั้งหมด ปัจจุบัน DE เลยเป็นที่ต้องการอย่างมาก
จริงๆแล้วอยากเขียนเรื่อง modern data stack และ concept การทำ data ใหม่ๆที่เกิดขึ้นในช่วง 2–3 ปีที่ผ่านมาด้วย แต่บทความนี้มันจะยาวเกินไปแล้ว เลยขอ throw หัวข้อให้ไปศึกษาเพิ่มเติมละกัน
Data mesh, Data lakehouse (Iceberg, Hudi, Delta lake), Data contract, Semantic layer, Data democratization
หวังว่าบทความนี้จะเป็นประโยชน์กับผู้อ่านทุกท่าน ขอบคุณค่ะ

Leave a Reply