Data Engineer Thailand ได้จัด Meetup ครั้งที่ 6 ทาง Discord เมื่อวันที่ 24 กันยายน 2024 ครั้งนี้พวกเราเชิญพี่ตั้ว ดิเรก ยิ้มละมัย Cloud Solution Manager จากบริษัท MFEC มาพูดในหัวข้อ Self-Service Data Platform

พี่ตั้วมาแชร์ความรู้และประสบการณ์การทำ Self-Service Data Platform เริ่มตั้งแต่อธิบายว่า Self-Service Data Platform คืออะไร ต้องใช้เครื่องมืออะไรบ้าง จะเปลี่ยนจาก Data Platform เดิมอย่างไร และเจอ Challenges อะไรบ้าง
บทความนี้เขียนจากการสรุป Meetup ของผู้เขียนและมีพี่ตั้วมาเป็น co-author ช่วยรวบรวมข้อมูลและตรวจสอบความถูกต้องด้วยค่ะ
- Self-Service Data Platform คืออะไร?
- หลักการของ Data Mesh
- เครื่องมือในการสร้าง Data Mesh
- อยากเปลี่ยนจากระบบเดิมมาเป็น Data Mesh ทำได้อย่างไร?
- Challenges ในการทำ Data Mesh
Self-Service Data Platform คืออะไร?
ชาว Data น่าจะเคยได้ยินคำว่า Data Lake กันอยู่แล้ว
Data Lake เป็นการเก็บข้อมูลจากทุกๆแหล่งมาไว้ในที่เดียว แล้วให้ผู้ใช้ข้อมูลมาดึงข้อมูลจาก Data Lake หรือ Data Warehouse ที่เป็นศูนย์รวมข้อมูลจากทุกที่ทุกทีม ระบบการเก็บข้อมูลแบบนี้เรียกว่า Centralized Data Platform ข้อดีของระบบแบบนี้คือ ทุกอย่างรวมไว้ในที่เดียว ใครอยากได้ข้อมูลอะไรก็มาเอาจากที่นี่ที่เดียวได้เลย
แต่ปัญหาของระบบนี้ที่เจอบ่อยๆคือ ทีมที่ดูแลระบบนี้ ซึ่งส่วนใหญ่คือทีม Data Engineer กลางต้องรับภาระทุกอย่าง ต้องรู้ว่าข้อมูลที่ทีม Business อยากได้อยู่ที่ไหน ข้อมูลมีความหมายอย่างไร ต้องรู้ Domain requirement ที่ต่างกันของแต่ละทีม (เช่น Marketing, Finance, Sales) ถ้ามีข้อมูลผิดก็ต้องหาว่าทำไมถึงผิดซึ่งจริงๆอาจจะผิดตั้งแต่ต้นทางเลยก็ได้ หลายๆครั้งทีม Data Engineer กลายเป็นคอขวดในการทำข้อมูลให้พร้อมใช้สำหรับทีม Business เพราะต้องทำหลายอย่าง เรียกได้ว่าเป็นทีมเดอะแบกของการทำข้อมูลในบริษัทเลยก็ว่าได้
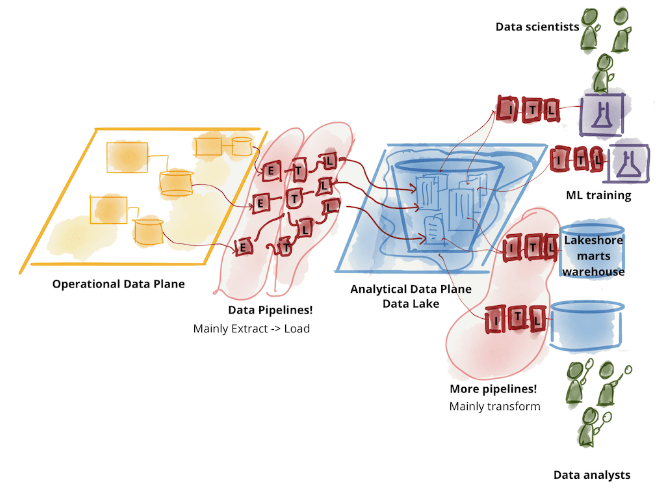
ในปี 2019 เลยมีคนเสนอให้ทำ Data Platform แบบ Decentralized เพื่อลดปัญหาข้างต้นที่กล่าวมา โดยใช้ชื่อว่า Data Mesh เป็นการกระจายการเก็บและจัดการข้อมูลไว้ตามทีมต่างๆแทนที่การเก็บรวมไว้ในที่เดียว โดยเขาเคลมว่า Data Mesh มีข้อดีคือ
- ความยืดหยุ่นสูง – แต่ละทีมสามารถจัดการข้อมูลของตัวเองได้อย่างอิสระ ทำให้ปรับเปลี่ยน พัฒนา และขยายระบบข้อมูลได้ง่ายขึ้น
- เพิ่มความเร็วในการเข้าถึงข้อมูล – ไม่ต้องรอข้อมูลจากส่วนกลาง ทำให้การวิเคราะห์ข้อมูลทำได้รวดเร็วขึ้น
- คุณภาพของข้อมูล – ข้อมูลถูกผลิตจากทีมที่รับผิดชอบข้อมูลนั้นๆ ข้อมูลจะมีความถูกต้องและน่าเชื่อถือมากขึ้น เพราะแต่ละทีมมี Domain expert อยู่แล้ว
- ปรับตัวได้ดีกับการเปลี่ยนแปลง – ถ้าองค์กรเติบโตหรือมีการเปลี่ยนแปลง สามารถปรับตัวได้ง่าย เพราะส่วนกลางไม่ต้องสร้าง Domain expert มาตอบโจทย์แต่ละทีม
สรุปโดย concept คือ Data Mesh จะให้ทีมต่างๆรับผิดชอบดูแลข้อมูลกันเอง ไม่ต้องมา bottleneck ที่ทีมกลางอีกต่อไป เลยเรียกอีกอย่างว่า Self-Service Data Platform (ในบทความต่อไปนี้จะใช้คำว่า Data Mesh แทน)
หลักการของ Data Mesh
ตอนที่มีคนเสนอ Data Mesh เขาได้กำหนดไว้ว่า Data Mesh จะต้องมีหลักการ 4 อย่างนี้
- Domain ownership – แต่ละ Domain หรือทีมเป็นเจ้าของข้อมูลของตัวเองและรับผิดชอบในการดูแลข้อมูลนั้น
- Data as a product – ข้อมูลถูกมองว่าเป็น Product ที่มีคุณภาพ มีการกำหนดมาตรฐานและมีการจัดการเหมือนกับ Product อื่นๆ มีการทำ Test/Feedback เพื่อปรับปรุงคุณภาพของข้อมูลให้ดีขึ้นอย่างต่อเนื่อง
- Self-serve data infrastructure – ทีมต่างๆสามารถเข้าถึงและใช้งานโครงสร้างพื้นฐานสำหรับการจัดการข้อมูลได้ด้วยตัวเอง
- Federated computational governance – มีการกำหนดกฎและมาตรฐานในการจัดทำและใช้ข้อมูลร่วมกันในระดับองค์กร และเพื่อบังคับใช้กฎต่างๆที่ตั้งขึ้นมาอย่างเคร่งครัด เขาเสนอว่าควรทำเป็น automate จึงเป็นที่มาของคำว่า computational
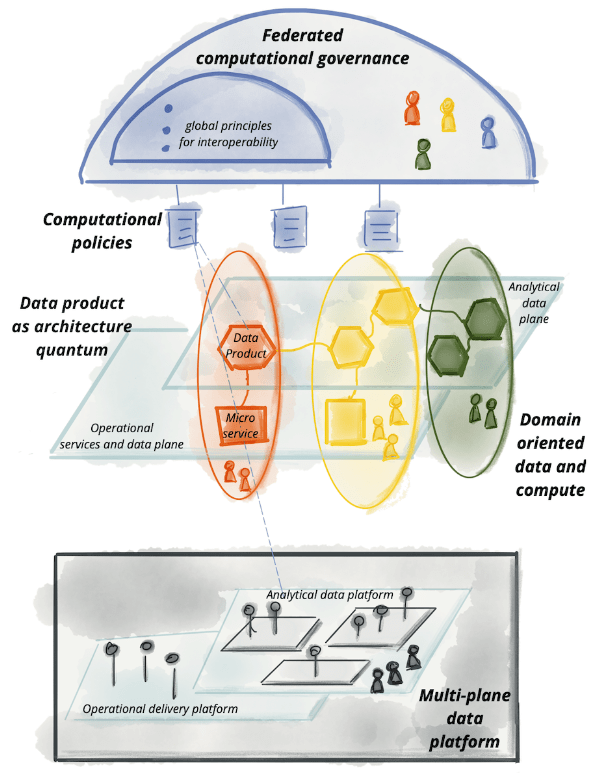
Data Mesh เป็นแนวคิดที่น่าสนใจสำหรับองค์กรที่ต้องการจัดการข้อมูลจำนวนมาก มีความหลากหลาย และทีมกลางในปัจจุบันกำลังประสบปัญหาทำงานไม่ทันหรือเป็นเดอะแบกอยู่ การนำ Data Mesh ไปใช้จะช่วยให้องค์กรมีความคล่องตัวมากขึ้น และสามารถนำข้อมูลไปใช้ประโยชน์ได้อย่างเต็มที่
ใน Meetup นี้ไม่ได้ลงลึกในแต่ละหลักการ แต่มีบทความอื่นๆอธิบายไว้เยอะแล้ว เพื่อนๆลอง search อ่านดูกันได้
เครื่องมือในการสร้าง Data Mesh
การสร้าง Data Mesh ใช้เครื่องมือและเทคโนโลยีหลายอย่างมาประยุกต์ใช้ร่วมกัน ตอนนี้ไม่มีเครื่องมือใดเครื่องมือหนึ่งที่สามารถสร้าง Data Mesh ได้เพียงอันเดียว เครื่องมือหลักๆที่เพิ่มมาจากการทำ Data Platform เดิม ได้แก่
Data Catalog
จากที่คุยกัน Data Catalog เป็นเครื่องมือที่สำคัญที่สุด ถือเป็นหัวใจสำคัญของ Data Mesh เลย Data Catalog เป็นเครื่องมือที่ใช้ในการจัดการและค้นหาข้อมูลทั้งหมด เมื่อมี Data Product หรือชุดข้อมูลใหม่ออกมา ข้อมูลทุกชุดจะต้องถูกบันทึกใน Data Catalog ว่าคือข้อมูลอะไร อยู่ทีมหรือ Domain ไหน ใครเป็น Owner ทำให้ผู้ใช้สามารถเข้าถึงและทำความเข้าใจข้อมูลได้ง่ายขึ้น ลดความซ้ำซ้อนของข้อมูล และลดการสร้างข้อมูลเองใหม่ตั้งแต่ต้น
ตัวอย่างเครื่องมือ : Apache Atlas, Collibra, Informatica, DataHub
Data Quality Tools
อันนี้เป็นสิ่งที่ต้องมีแน่นอนใน Data Mesh เพราะเขาเคลมว่ากระจายการจัดการข้อมูลกันแล้วข้อมูลต้องดีขึ้นนะ ก่อนที่แต่ละทีมหรือ Domain จะปล่อยข้อมูลออกมาให้ทุกคนพร้อมใช้ ต้องมีการตรวจสอบคุณภาพข้อมูลก่อน ถ้ามีข้อมูลผิด Data owner จะต้องเป็นคนรับผิดชอบและปรับปรุง ไม่ใช่ทีมกลางอีกต่อไป
ตัวอย่างเครื่องมือ : Great Expectation, Talend
Data Governance Platform
เป็นเครื่องมือที่ใช้ในการกำหนดกฎเกณฑ์และมาตรฐานในการจัดการข้อมูล และกำหนดสิทธิ์ในการเข้าถึงข้อมูลแต่ละชุด ช่วยให้มั่นใจว่าข้อมูลมีความถูกต้องและปลอดภัย
ตัวอย่างเครื่องมือ : Collibra, Informatica, Alation
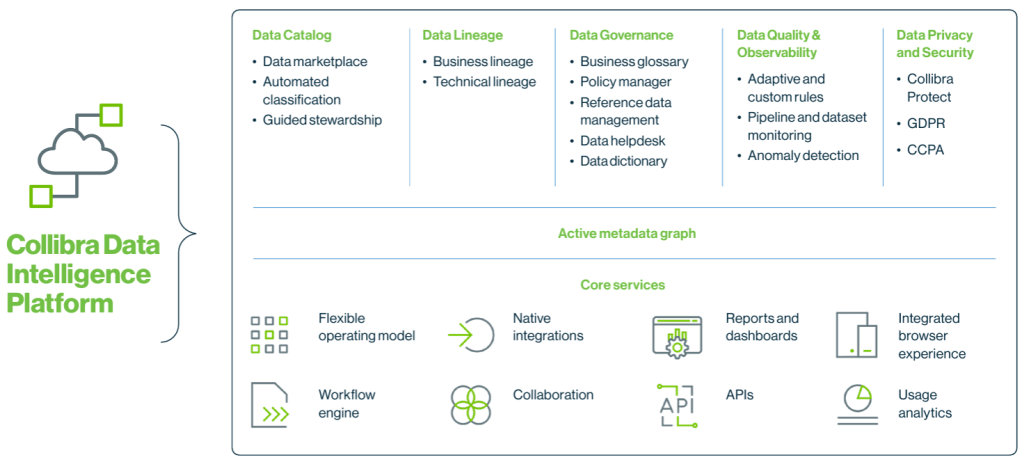
เนื่องจากมีเครื่องมือให้เลือกใช้เยอะ การเลือกเครื่องมือที่เหมาะสมจะขึ้นอยู่กับขนาดและความซับซ้อนของข้อมูล งบประมาณ และความสามารถของพนักงาน ซึ่งอาจจะแตกต่างกันตาม condition ของแต่ละบริษัท
อยากเปลี่ยนจากระบบเดิมมาเป็น Data Mesh ทำได้อย่างไร?
การเปลี่ยนแปลงจากระบบเดิมมาสู่ Data Mesh เป็นการเปลี่ยนวิธีการบริหารจัดการข้อมูลภายในองค์กร แต่ไม่ใช่การปรับเปลี่ยนแค่ทางเทคโนโลยีเท่านั้น จะต้องมีการปรับเปลี่ยนทั้งวัฒนธรรมการใช้ข้อมูลในองค์กร กระบวนการ ความรับผิดชอบ และมีเครื่องมือมาช่วยเพิ่มเติม
เนื่องจากเป็นการเปลี่ยนแปลงระดับใหญ่ จึงต้องใช้ความระมัดระวังและการวางแผนอย่างรอบคอบ พี่ตั้วแนะนำว่า “ค่อยเป็นค่อยไป” ลองทำทีละทีม เริ่มจากทีมที่ต้องการใช้ข้อมูลมากที่สุดหรือส่งผลต่อองค์กรในภาพ productivity/revenue ก่อน
พี่ตั้วได้แชร์ขั้นตอนในการเปลี่ยนแปลงที่เคยทำมาดังนี้
Gap analysis
ลองประเมินก่อนว่าตอนนี้ระบบข้อมูลของเราเป็นอย่างไร และท้ายที่สุดจะไปถึง Mesh ได้มี gap อะไรบ้าง แต่พี่ตั้วแนะนำว่าให้ค่อยๆแบ่งทำไปทีละ step ย่อยๆ เพราะถ้าเปลี่ยนทีเดียวคือตายแน่นอน ส่วนที่ควรประเมิน เช่น
- ระบบข้อมูลเดิมทั้งหมดและกระบวนการทำงาน
- ระบุความต้องการของธุรกิจให้ชัดเจนในแต่ละ step
- ประเมินความพร้อมของพนักงาน เพราะ Data Mesh จะกระจายการทำข้อมูลไปที่ทีมต่างๆ จะต้องดูด้วยว่าแต่ละทีมมีความรู้ในเรื่องของการจัดการข้อมูลแล้วหรือยัง
Design Data Mesh Architecture
ตอนที่พี่ตั้วทำคือ เชิญทุกทีมมานั่งจับเข่าคุยกันแล้วออกแบบในกระดาษก่อน โดยเรียกเฉพาะทีมที่สำคัญๆที่ใช้ข้อมูลเยอะๆ ร่างภาพใหญ่ไว้คร่าวๆก่อน แล้วค่อยๆเติมจุดเล็กๆแต่ละจุด โดยหัวข้อที่ควรอยู่ในการออกแบบคือ
- กำหนด Domain – แบ่งข้อมูลออกเป็น Domain ต่าง ๆ ตามแนวทางธุรกิจ (Business strategy)
- ออกแบบ Data product – Data product คือข้อมูลที่ทำออกมาแล้วใช้ประโยชน์ได้เลย เหมือนของพร้อมขาย ต้องกำหนดรูปแบบของข้อมูลที่แต่ละ Domain จะปล่อยออกมา
- กำหนดกฎเกณฑ์และมาตรฐาน (Governance) – กำหนดแนวทางในการจัดการข้อมูล เช่น คุณภาพข้อมูล ความปลอดภัย และการเข้าถึงข้อมูล แนะนำให้ตั้งเป็นคณะกรรมการ (Committee) เพื่อร่วมกันทำงานและเปลี่ยนแปลง เพราะช่วงแรกๆ จะเกิดช่องว่างของ Data owner ว่าใครต้องรับผิดชอบข้อมูลที่ผลิตออกมา
- เลือกเครื่องมือและเทคโนโลยี – เลือกเครื่องมือที่เหมาะสมกับองค์กร พอกระจายการทำข้อมูลแล้ว ไม่ใช่ว่าทีมไหนจะเลือกใช้เครื่องมืออะไรก็ได้ ต้องมีเครื่องมือที่ common กันอยู่ ไม่งั้นการจัดการจะยุ่งยากมาก
Develop & Test
พอออกแบบเสร็จแล้วก็มาค่อยๆเริ่มทำทีละทีมหรือ Domain ทีละชุดข้อมูล ลองสร้าง Data pipeline ของแต่ละ Domain และ Data Catalog แล้วทดสอบระบบทั้งหมดเพื่อให้มั่นใจว่าทำงานได้ตามที่ต้องการ ถ้าทดสอบผ่านก็ค่อยๆขยายไป
Adopt & Manage
อย่างที่กล่าวไปข้างต้นว่าการเปลี่ยนมาใช้ Data Mesh ไม่ใช่แค่เปลี่ยนทางเทคโนโลยี แต่เปลี่ยนวัฒนธรรมการใช้ข้อมูลและกระบวนการด้วย
- กำหนดกระบวนการทำงานใหม่ที่สอดคล้องกับ Data Mesh แต่ไม่ละเลยกระบวนการทำงานเดิมมากเกินไป เพราะวัฒนธรรมเดิมเปลี่ยนทันทียาก
- ค่อยๆให้ความรู้และฝึกอบรมพนักงานในการใช้งาน Data Mesh พนักงานเดิมมีงานในมืออยู่แล้ว ต้องค่อยๆวางแผน resource utilization เช่น จัดพนักงานชั่วคราวมาช่วยแบ่งเบางานที่เพิ่มขึ้น
- ติดตามประเมินผลและปรับปรุงระบบให้ดียิ่งขึ้น ตรงนี้พี่ตั้วแนะนำใช้เป็นคณะกรรมการร่วม (ทั้งส่วนกลางและทีมต่างๆ) มาร่วมกันทำอย่างต่อเนื่อง เพราะการสร้างสิ่งใหม่มักจะเกิดช่องว่างและขั้นตอนที่สิ้นเปลืองเสมอ ต้องช่วยกันจัดการเรื่องระหว่างทางเหล่านั้น
อันนี้พี่ตั้วแชร์คร่าวๆจากที่เคยทำมา แต่ละองค์กรอาจมีขั้นตอนมากกว่านี้ อย่างภาพด้านล่างก็เป็นอีกแนวทางหนึ่งที่มีคนเขียนแชร์ไว้ โดยรวมสอดคล้องกับที่พี่ตั้วแชร์ใน Meetup หากผู้อ่านสนใจสามารถอ่านเพิ่มได้ในลิ้งใต้ภาพ
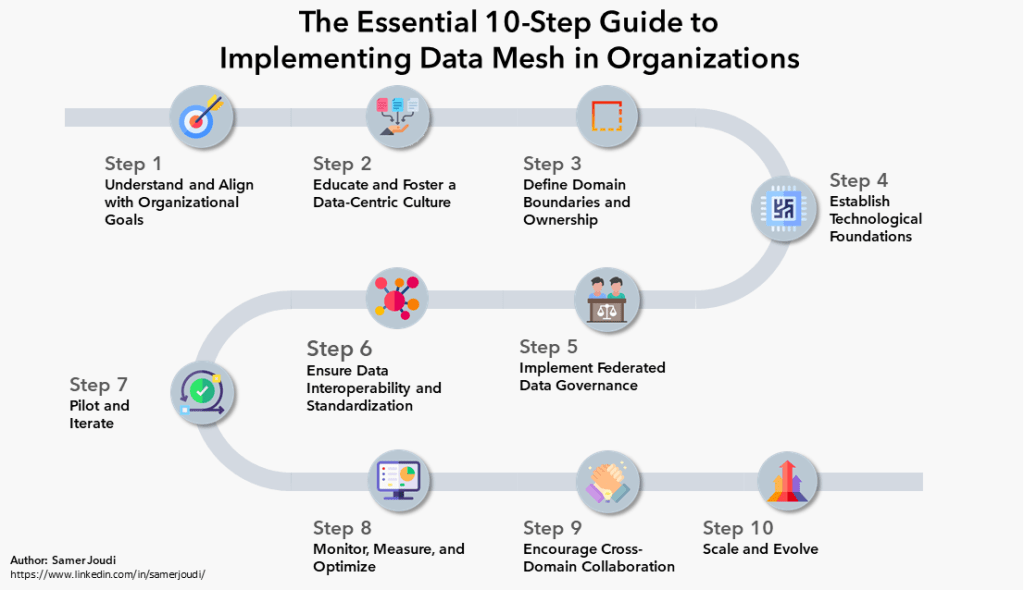
พี่ตั้วเสริมว่า ถึงแม้ concept ของ Data Mesh จะเป็น Decentralized ทั้งหมด แต่พอทำจริงๆแล้วก็ยังคงต้องมี Centralized หรือ Data Lake กลางอยู่ดี เพราะบางทีพอทดสอบไป คนยังชอบ Data Lake มากกว่า หรือบางทีก็มีข้อมูลกลางที่ทุกทีมต้องใช้ร่วมกัน ไม่สามารถแบ่งทีมได้ เช่น ข้อมูลยอดขาย ข้อมูลสินค้า ที่พอทำแบบ Decentralized แล้วกลับมาไว้ที่ส่วนกลางจะสะดวกและเข้าถึงง่ายกว่า
การเปลี่ยนแปลงจากระบบเดิมมาเป็น Data Mesh เป็นการลงทุนระยะยาว ต้องคำนึงถึงการเปลี่ยนแปลงวัฒนธรรมองค์กรและต้องได้รับความร่วมมือจากทุกฝ่าย พี่ตั้วบอกเหมือนวิ่งมาราธอน หืดขึ้นคอกันเลยทีเดียว
Challenges ในการทำ Data Mesh
การเปลี่ยนแปลงย่อมมีปัญหาตามมาเสมอ หลังจากที่พี่ตั้วลองผิดลองถูกมาหลายครั้ง ก็ได้แชร์ปัญหาที่เคยเจอ ได้แก่
ออกแบบ Domain ไม่ชัดเจน
ข้อมูลที่อยู่ใน Data Mesh ทั้งหมดจะต้องมี Domain หากแบ่ง Domain ของข้อมูลไม่ชัดเจน หรือไม่สอดคล้องกับบริบททางธุรกิจ ผู้ใช้ข้อมูลอาจสับสนในการใช้และค้นหาข้อมูลที่ต้องการ ทำให้การใช้งาน Data Mesh กลายเป็นอุปสรรคมากกว่าเป็นประโยชน์ พี่ตั้วแนะนำว่า การแบ่ง Domain ให้ตั้งจากแผนธุรกิจหรือโครงสร้างของหน่วยงานที่มี
คุณภาพของ Data Product ไม่ดี
หาก Data Product มีคุณภาพไม่ดี เช่น ข้อมูลไม่ถูกต้อง ไม่ครบถ้วน หรือไม่มีการอัปเดต และที่สำคัญไม่มีคณะกรรมการหรือผู้รับผิดชอบในการตรวจสอบคุณภาพข้อมูลอย่างสม่ำเสมอ ผู้ใช้งานจะไม่สามารถ trust ข้อมูลที่ได้มาและไม่กล้าที่จะนำไปใช้ในการตัดสินใจ
การเข้าถึงข้อมูลจำกัด/ไม่จำกัดจนเกินไป
มีคนเข้าใจผิดว่าเปลี่ยนเป็น Data Mesh แล้วจะเข้าถึงข้อมูลชุดไหนก็ได้ ซึ่งไม่เป็นความจริง ยังมีการครอบสิทธิ์ข้อมูลทุกชุดอยู่ แต่หากกำหนดสิทธิ์ในการเข้าถึงข้อมูลทำได้ไม่ดี ผู้ใช้งานบางกลุ่มอาจไม่สามารถเข้าถึงข้อมูลที่ตนเองต้องการได้ ทำให้ไม่สามารถทำงานได้อย่างเต็มประสิทธิภาพ หรือผู้ใช้งานบางกลุ่มเข้าถึงข้อมูลได้เกินบทบาทหน้าที่ ก็มีความเสี่ยงทำให้ข้อมูลรั่วไหลได้
ขาดเอกสารประกอบ (Document)
หาก Data Product ไม่มีเอกสารประกอบหรือคำอธิบายที่ชัดเจน ผู้ใช้งานจะไม่เข้าใจความหมายของข้อมูลและไม่รู้ว่าจะนำข้อมูลไปใช้อย่างไร ใน Data Lake แบบเดิมส่วนกลางเป็นคนจัดการให้ แต่เมื่อกระจายความรับผิดชอบแล้ว การทำเอกสารสำคัญเหล่านั้นจะไปอยู่ที่ Domain แทน
ขาดเครื่องมือที่ใช้งานง่าย
เนื่องจากการทำข้อมูลจะตกไปอยู่ที่ Domain หรือทีมต่างๆแทนทีมกลาง หากเครื่องมือที่ใช้มีความหลากหลายเกินไปหรือซับซ้อนเกินไป จะทำให้ใช้งานยาก ผู้ใช้งานจะไม่ต้องการเรียนรู้วิธีการใช้งาน และหันไปขอความช่วยเหลือจากส่วนกลางแทน (อ่าว กลับมาที่ส่วนกลางซะงั้น)
การนำ Data Mesh มาใช้สามารถสร้างประโยชน์ให้กับองค์กรได้อย่างมาก แต่ต้องมีการวางแผนและออกแบบอย่างรอบคอบ หากต้องการให้ Self-Service ไปต่อได้ ต้องให้ความสำคัญกับบุคคลากร ปรับวัฒนธรรมองค์กร คุณภาพของข้อมูล การเข้าถึงข้อมูล และความง่ายในการใช้งาน

Leave a Reply