
สวัสดีค่ะ เราชื่อแก้ว ปัจจุบันเป็น Director of Data Engineering อยู่ที่บริษัท NocNoc ในบทความนี้เราจะเล่าถึงการสร้าง Data Lakehouse Architecture ที่อยู่บน AWS ทั้งหมด
หลายคนอาจจะมีคำถามว่าทำไมไม่ใช้ Databricks ล่ะ ก็ต้องยอมรับเลยว่า Databricks มีราคาค่อนข้างแพงเมื่อเทียบกับขนาดบริษัท จำนวนผู้ใช้งานและ Budget ที่เรามีอยู่ เราก็เลยลองหา Services ของ AWS แล้วก็พบว่ามีความเป็นไปได้ที่จะทำสิ่งที่คล้ายๆ กันได้ ก็เลยเอามาเล่าให้ฟังในบทความนี้ เผื่อจะเป็น Case Study ให้กับคนที่สนใจไปลองกันได้ค่ะ
บทความนี้จะแบ่งหัวข้อตามนี้
- Data Lakehouse คืออะไร? Apache Iceberg คืออะไร?
- Data Lakehouse Architecture on AWS
- Consideration & Alternative— ทุกอย่างมีข้อดีข้อเสีย เป็นสิ่งที่ต้องประเมินเทียบกันก่อนเลือกใช้เทคโนโลยี
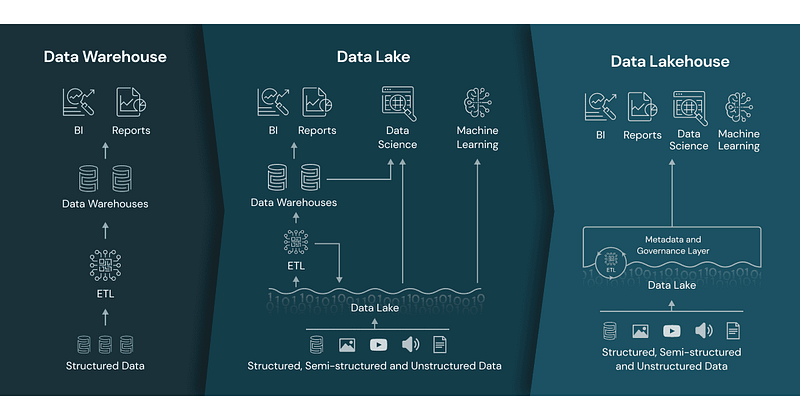
Data Lakehouse & Apache Iceberg
Data Lakehouse เกิดจากการนำข้อดีของ Data Warehouse และ Data Lake มารวมกัน ซึ่งแต่ละอันมีข้อดีข้อเสียดังนี้
Data Lakehouse
Data Warehouse
- เก็บข้อมูลเป็นแบบ structured data ง่ายสำหรับการทำ BI หรือ analytics
- ไม่เหมาะกับข้อมูล realtime ที่มี transaction มากๆ และเป็นข้อมูล raw เนื่องจากข้อจำกัดในด้าน storage ซึ่งถ้าเราใส่ข้อมูล raw เยอะเข้าไปมากๆ storage ก็จะเต็มไว
- ถ้า warehouse แบบเก่าๆ storage กับ compute จะ coupling กัน ถึงแม้เราจะใช้ compute power ไม่ถึง แต่ storage เต็มแล้วก็ต้องขยายทั้งเครื่อง หรือในทางกลับกัน ถ้าใช้ compute power เกิน แต่ storage ยังว่าง ยังไงก็ต้องขยายเครื่อง
Data Lake
- เก็บได้ทั้ง structured และ unstructured data โดยจะเก็บเป็น file เหมาะสำหรับ data scientist
- แต่ไม่เหมาะกับการทำ BI และ analytics เพราะจะ query ยาก สุดท้ายก็ต้องทำให้เป็น structured data แล้วไปเก็บไว้ใน warehouse อยู่ดี ซึ่งจะทำให้เกิด duplicated data ระหว่าง warehouse กับ lake ได้ และอาจเกิด data inconsistency ด้วย
- ราคาในการเก็บข้อมูลถูกกว่า warehouse เพราะเก็บเป็น file เพราะฉะนั้นจะเก็บข้อมูลเยอะเท่าไหร่ก็ได้ cost ต่ำมาก
- ไม่สามารถทำ ACID transaction ได้ เนื่องจากข้อมูลเก็บเป็น file จะทำ insert, update, delete ก็จะทำได้ค่อนข้างยาก
Data Lakehouse เลยออกแบบมาเพื่อจัดการปัญหาเหล่านี้ และมีคุณสมบัติดังนี้
- Unified data — ไม่ว่าจะเป็น unstructured หรือ structured data เก็บไว้ที่นี่ ทำให้ BI, analytics, data scientist สามารถเข้าถึงข้อมูลได้ที่นี่ที่เดียว และเป็น source of truth ของข้อมูล
- Support ACID transaction — ใน lakehouse เราสามารถจัดการกับ data ได้เหมือนใน databaseไม่ว่าจะเป็น insert, upsert, delete row, update row
- Decoupling storage and computation layer — ทำให้เราสามารถ manage ส่วนต่างได้ดี scale แต่ละ component เท่าที่จำเป็นได้
- Metadata layer — อันนี้เป็น requirement ของ lakehouse เลยค่ะ เป็นสิ่งที่เก็บ changelog ที่เกิดขึ้นใน lake ของเรา เหมือน audit log ของ data ทำให้เราสามารถทำ governace ได้ดีขึ้น
จริงๆ Feature ของ Data Lakehouse ยังมีมากกว่านี้อีก แต่อันนี้เลือกมาแค่อันที่สำคัญเท่านั้น หากใครสนใจสามารถหาอ่านเพิ่มเติมได้ค่ะ
Apache Iceberg

แล้ว Iceberg เกี่ยวอะไรกับ Data Lakehouse ล่ะ? อย่างที่กล่าวไปข้างต้นจะเห็นว่า lakehouse จะมี feature เพิ่มเติมมาจาก data lake เช่น ACID transaction, metadata layer ซึ่งลำพัง file format ปกติ เช่น parquet, orc, avro ไม่สามารถทำตรงนี้ได้ จึงมี framework มาจัดการ file ขึ้นมา โดยในปัจจุบันที่นิยม คือ Delta Lake, Apache Hudi และ Apache Iceberg ทั้ง 3 ตัวนี้จะมี concept และ feature คล้ายๆ กันและเป็น open-source เหมือนกัน การจะสร้าง Data Lakehouse ได้เลยต้องใช้ 1 ใน 3 ตัวนี้
เราเลือก Apache Iceberg มาลองทำก่อน เพราะว่า setup ง่าย ใช้งานง่าย ไม่ต้อง tune parameter เยอะ ทำให้เราสามารถขึ้นระบบได้เร็วค่ะ
เราจะไม่อธิบายว่า Iceberg ทำงานยังไงในบทความนี้ แต่จะยก feature หลักๆ ที่ทำให้ชีวิต data engineer สบายขึ้นและ manage data ได้ดีขึ้น
- ACID Transaction — สามารถ delete, update row ด้วยคำสั่งง่ายๆ
- Schema evolution — add, drop, rename, update column โดยไม่กระทบ data
- Time travel — Iceberg จะเก็บ data ทุก version ของเราเอาไว้ เราสามารถ rollback data ไป version ก่อนๆ ที่เราต้องการได้ สมมติว่า version ปัจจุบันมี data ผิด เราก็เอา data ย้อนหลังมาให้ user ใช้ไปก่อนได้ อีก use case หนึ่งที่ได้ใช้คือเอาข้อมูลของเมื่อวานกับวันนี้มาหา diff กันได้ค่ะ
- Hidden partitioning — โดยปกติถ้าจะทำ partition จะต้องสร้าง column ใหม่มาสำหรับทำ partition แต่ของ Iceberg ใช้ column ที่มีอยู่ทำ partition ได้เลย
- Indexing — ปกติจะทำ index บน file ไม่ได้ แต่ Iceberg ก็มีแอบๆ ทำอยู่ ทำให้ performance ในการ join ดีขึ้น
- Metadata file — เป็นเหมือน audit log ของ table โดย file นี้จะเก็บหมดเลยว่ามี change อะไรบ้าง ถ้ามี schema change มันจะเก็บ historical schema ไว้ด้วย ทำให้ track ได้หมดเลยว่าเกิดอะไรขึ้นกับ table บ้าง รวมถึงข้อมูล data version เก่าๆ ด้วย
Feature ยังมีอีกเยอะ แต่เท่านี้ก็ทำให้ data engineer ทำ data management ได้ง่ายขึ้นมากแล้วค่ะ
พอรู้จัก Data Lakehouse และ Iceberg แล้ว มาลองดูกันดีกว่าว่าเราออกแบบ Architecture ยังไงกัน
Data Lakehouse Architecture on AWS
ภาพด้านล่างจะแสดง Overview ของ Data Lakehouse Architecture โดยจะใช้ service ของ AWS ทั้งหมดเลย
หลักๆ จะใช้
- S3 เป็น storage ของการเก็บ file ทั้งหมด
- EMR เป็น managed-service สำหรับการทำ big data solution ของ AWS ซึ่งในที่นี้เราจะใช้เป็น Spark Cluster และ Trino
- Glue Data Catalog ใช้เป็นที่สำหรับเก็บ metadata ในการทำ Data Lakehouse

ต่อไปจะอธิบายว่าแต่ละ layer ทำงานยังไงและเชื่อมต่อกันยังไงค่ะ
Storage Layer
ส่วนนี้จะเป็นส่วนที่เก็บข้อมูลหรือ file ทั้งหมด เราประยุกต์ใช้ Medallion Architecture จาก Databricks โดยแบ่ง data ออกเป็น zone ตาม quality ของข้อมูล

- Bronze — ส่วนนี้คือส่วนที่ดึงมาจาก source ตรงๆ เลยโดยที่ยังไม่มีการทำ transform ใดๆ ทั้งสิ้น เธอมายังไงฉันก็เก็บเอาไว้อย่างงั้น
- Silver — ส่วนนี้จะเก็บข้อมูลที่ทำการ transform แล้วและพร้อมใช้ใน zone ต่อไป เช่น แปลงเวลาจาก UTC เป็น Asia/Bangkok, cast type ให้ถูกต้อง, rename column ให้เข้าใจง่ายและเป็น snake case, handle data ที่ source ส่งมาแบบเอ๋อๆ, etc. มากมาย (Add-on: ส่วนนี้ยังเป็นส่วนที่เราทำ data modeling ง่ายๆ จัดข้อมูลเป็นหมวดหมู่ เพื่อให้ user explore data ได้ง่ายขึ้น เนื่องจากบางที datasource จาก tech จะ normalized มากๆ ข้อมูลกระจัดกระจายทำให้ user ต้อง join เยอะกว่าจะเจอข้อมูลที่อยากได้ เราเลยทำเตรียมไว้ให้ก่อน)
- Gold — ส่วนนี้จะเป็นส่วนที่ user เอาข้อมูลจาก silver มาทำการ aggreate ใส่ business logic และทำเป็น table/view เพื่อเอาไปใช้ทำ analytic หรือสร้าง dashboard
Processing Layer
ส่วนนี้เราเลือกใช้ Spark ในการ process ข้อมูล โดยใช้ EMR เป็น Spark cluster ซึ่ง EMR ก็ดีมากๆ ที่ลง Apache Iceberg มาให้ด้วย ทำให้เราสามารถใช้ Spark กับ Iceberg ได้เลย แถม EMR ยัง upgrade version ของ Iceberg ตลอดด้วย ทำให้เวลามี feature อะไรใหม่ๆ ของ Iceberg เราก็สามารถเอามาใช้ได้ทันที
ใน layer นี้เราจะต้อง config ให้ Spark ไปเขียน data ที่ S3 และส่ง metadata ไปให้ Glue ด้วย ซึ่งสามารถใส่ config ได้ตรง SparkSession
# This is just example on EMR
"hive.metastore.client.factory.class": "com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory",
"spark.sql.catalog.<catalog_name>": "org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.<catalog_name>.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"spark.sql.catalog.<catalog_name>.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"spark.sql.catalog.<catalog_name>.warehouse":"s3://<lakehouse_path>/",
"spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions"Metadata Layer
ส่วนสำคัญของ Lakehouse คือ layer นี้ค่ะ โดยส่วนนี้จะเป็นการทำงานร่วมกันของ Iceberg และ Glue Catalog ซึ่งเป็นเหมือน discovery service
อธิบายง่ายๆ คือเวลาที่ Spark write หรือ update iceberg table ตัว Spark จะทำการ register ข้อมูลของ Iceberg ไปที่ Glue โดย Glue จะไม่ได้เก็บ data อะไรแต่จะเก็บเฉพาะ metadata file เท่านั้น ซึ่งจะมีหน้าตาแบบรูปด้านล่าง

ทีนี้เวลามีคนมาอ่าน table นี้ Glue ก็จะให้ metadata file นี้ไปซึ่งในนี้จะบอกว่าต้องไปอ่าน data file ไหนเพื่อให้ได้ข้อมูลที่ต้องการ การทำงานระหว่าง S3, Spark, Glue จะประมาณรูปด้านล่างค่ะ
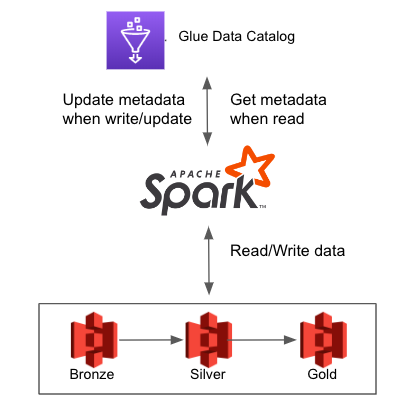
Note: จริงๆ การทำงานเบื้องหลังของ Iceberg ซับซ้อนกว่านี้ค่ะ อันนี้อธิบายเพื่อให้เห็นภาพได้ง่ายขึ้น
นอกจากเราจะใช้ Glue เก็บ metadata file แล้ว เรายังใช้ Glue ในการกำหนด database หรือ schema ด้วยซึ่งจะ link กับ S3 structure ที่เราวางไว้

การสร้าง database บน Glue ไม่ได้เป็นการสร้าง database instance จริงๆ แต่เป็นการบอกว่าถ้ามีการเรียก database ตัวนี้จะต้องไปอ่านหรือเขียน file ที่ S3 path ไหน เป็น metadata layer ครอบตัว S3 อีกที ซึ่งตัว database ที่เราสร้างไว้ใน Glue ก็สามารถเอาไปทำ governance ต่อได้ โดยเราสามารถกำหนดได้ว่า user กลุ่มไหนจะเห็น/ดึง/เขียนข้อมูลใน database ไหนได้บ้าง
Query Engine
ตอนนี้เรามี data บน S3 แล้วแต่มันเก็บเป็น file เราจะ query ออกมาใช้อย่างไร
ส่วนนี้เราเลือกใช้ Trino (PrestoDB) เป็น Distributed SQL query engine ที่ query ข้อมูลขนาดใหญ่ได้เร็วและที่สำคัญคือ support Iceberg! และพอดี EMR ก็มี Trino ให้ใช้อยู่แล้ว เราก็เลยเลือกใช้ EMR มาเป็นทั้ง Spark cluster แล้วก็ Trino cluster ไปเลย
การทำงานก็คล้ายๆ กับที่อธิบายไปข้างต้นค่ะ เรา setup Trino ให้ต่อกับ Glue Catalog ทีนี้พอมี query เรียก Iceberg table มันก็จะวิ่งไปหา Glue ก่อนให้ได้ metadata file มา จากนั้น Trino เองก็จะรู้แล้วว่าต้องไปอ่าน file ไหนเพื่อส่งออกมาเป็น table ให้ user
อีกเหตุผลหนึ่งที่เราเลือก Trino มาเป็น query engine คือ Trino สามารถดึงข้อมูลจาก Google Sheet เข้ามาเป็น table ได้และสามารถใช้ join กับ Iceberg table ได้ด้วย ถ้าทำงานใน startup ก็อาจจะพอรู้ว่า business users ทำงานบน Google Sheet เยอะมาก แล้วก็อยากเอาข้อมูลจาก Google Sheet เข้าระบบเพื่อมาทำ report หรือ dashboard ให้สมบูรณ์ ซึ่ง Trino สามารถทำตรงนี้ได้โดยลดงานของ data engineer ได้ค่ะ
ด้วยการออกแบบนี้เลยทำให้ Trino เป็นเหมือน entry point ในการเข้าถึงข้อมูลทุกอย่างค่ะ
Note: Feature ที่ join ข้อมูลข้าม datasource กันได้เรียกว่า Federated queries ถ้าสนใจสามารถหาอ่านเพิ่มเติมได้ค่ะ
Consumption Layer
สุดท้ายแล้ว user จะ query ข้อมูลออกไปได้อย่างไร
ต้องบอกก่อนว่า Trino เป็นแค่ query engine แต่ไม่มีที่ให้เขียน SQL query ดังนั้นเราต้องหาหน้ากากที่จะให้ user เขียน query แล้วส่งไปให้ที่ Trino
เราเลือกใช้ Apache Superset เป็น open-source ที่มี SQL Lab พื้นที่ให้เขียน SQL แล้ว set connection ไปให้ไปต่อกับ Trino ทำให้ user สามารถ query ดูข้อมูลที่อยู่ในระบบได้ ปั้นข้อมูลแล้ว create view สำหรับเอาไปทำ dashboard ต่อได้ หรือจะใช้ Tableau มาต่อกับ Trino ก็ได้เหมือนกัน ส่วน data scientist ก็สามารถดึงข้อมูลจาก Trino ด้วย python ได้โดยใช้ jdbc ค่ะ
ในส่วนของการอ่านข้อมูลจะมี flow ตามรูปด้านล่างค่ะ
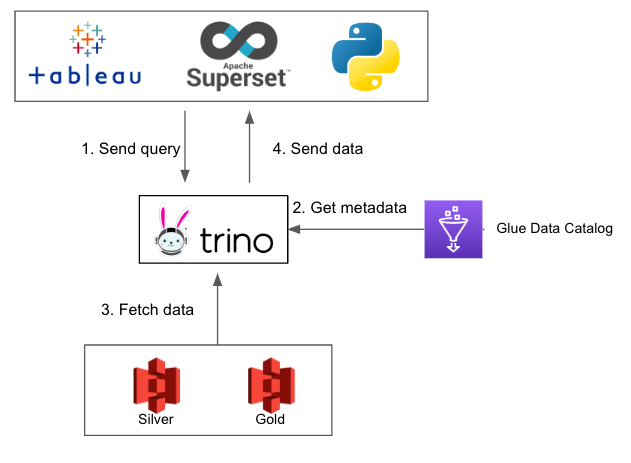
จาก design ข้างต้นจะเห็นว่าเราสามารถทำ Data Lakehouse ได้ด้วยใช้ AWS services ทั้งหมด
- ไม่มี database instance เพิ่ม ทุกอย่างเก็บเป็น file บน S3 ทำให้ cost การเก็บ data ต่ำมากๆ
- Decoupling storage and computation โดยเก็บ file ทั้งหมดไว้ที่ S3 เวลา Spark ทำงานก็มาอ่านที่ S3 เสร็จก็เขียนกลับลง S3 ไม่มีการเก็บข้อมูลใน Spark ไม่มี dependency กัน ส่วน Trino ก็มาอ่าน file จาก S3 ที่เดียวกัน ซึ่งทั้ง Spark และ Trino ทำงานบน EMR
- ใช้ Apache Iceberg มาเพื่อทำ ACID transaction กับ file ได้เหมือนใน relational database
- ใช้ Glue ในการทำ metadata layer เก็บ metadata file จาก Iceberg กับสร้าง database สำหรับการทำ governance
Consideration & Alternative
ปัจจุบันที่ NocNoc ได้ใช้ Data Lakehouse ตามที่ออกแบบมาข้างต้นแล้ว ในส่วนของ user อาจจะไม่ได้เห็นถึงการเปลี่ยนแปลงมาก แต่ในฝั่งของ data engineer เราดูแลและ maintain ระบบได้ดีขึ้น การใช้ Iceberg ทำให้แก้ปัญหาเวลาที่มี data error ได้ง่ายขึ้นและเร็วขึ้น
แต่การเลือกใช้ technology ก็อาจจะต้องคำนึงถึงปัจจัยหลายๆ อย่าง
Iceberg or Hudi
ใน context ของเรามีข้อจำกัดทางด้านเวลาและ use case ของเรายังไม่มี realtime เราเลยเลือกใช้ Iceberg ที่มี learning curve น้อยกว่า ด้วย performance ที่ยังพอรับได้ แต่ถ้าคุณจะทำ realtime เราก็อยากแนะนำให้ไปศึกษา Hudi ซึ่งออกแบบมาสำหรับการทำ realtime มากกว่า
EMR
ด้วยข้อจำกัดทางด้าน budget เราเลยเลือก EMR ที่เป็น fixed cost มาลองก่อน EMR เป็น manged service ที่จัดการลง software ที่จำเป็นและ setup cluster ให้แต่ยังมีข้อจำกัดดังนี้
- Config ที่ EMR ให้มายังไม่ได้ตอบโจทย์ use case ของเราทั้งหมดและการที่จะให้ EMR ใช้ Iceberg ได้นั้น เรายังต้องเข้าไป config หลายๆ อย่างใน EMR เพื่อให้ทำงานแบบที่เราต้องการ
- ถึงจะเป็น fix cost แต่เรายังต้องทำ sizing ของ cluster คือต้องเลือกเครื่อง ec2 ประเมิน core และ mem ที่จะต้องใช้ หากเลือกเครื่องเล็ก resource ไม่พอก็อาจจะทำให้ pipeline พัง หรือถ้าเลือกเครื่องใหญ่เกินไปก็จะทำให้เปลืองเงินเปล่าๆ ซึ่งส่วนนี้ต้องทำควบคู่กับการ optimize spark resource ของ job ด้วย
Alternative — ถ้าไม่อยากปวดหัวกับ EMR ก็ยังพอมี Alternative solution อยู่คือการใช้ Serverless ที่เราไม่ต้องดูแลเอง เช่น Glue ETL job ที่สามารถใช้ Spark และ support Iceberg เหมือนกัน แต่ก็แลกมาด้วย uncontrollable cost ยิ่งถ้ามี job เยอะขึ้นหรือ data ที่ต้อง process มีขนาดใหญ่ขึ้น cost ก็จะพุ่งกระฉูดเลยทีเดียว เพราะมันคิดเป็น DPU (data processing unit) เท่าที่อ่านก็คือแพงกว่า EMR แน่นอน
Query Engine
เราเลือก Trino on EMR เพราะฉะนั้นก็จะเจอปัญหาคล้ายด้านบนค่ะ บวกกับต้องไปเรียนรู้และ config Trino เพิ่มเติมด้วย
Alternative — จริงๆ จะไปใช้ Athena ก็ได้ แต่จากประสบการณ์ UI ไม่ค่อยกับ friendly กับ user เท่าไหร่ และก็เหมือน BigQuery คือ pay-per-use ก็จะขึ้นอยู่กับ user เลยว่า query ข้อมูลใหญ่ขนาดไหน join เยอะและซับซ้อนแค่ไหน
จากบทความนี้หวังว่าผู้อ่านจะเข้าใจ concept และการทำงานของ Data Lakehouse มากขึ้น ส่วนการออกแบบในบทความนี้เป็นเพียงตัวอย่างที่เราใช้ที่ NocNoc เท่านั้น แต่ละบริษัทอาจจะมีข้อจำกัดและ requirement ที่แตกต่างกันไป ผู้อ่านสามารถนำไป ปรับใช้ตามความเหมาะสมได้ค่ะ

Leave a Reply