Tools ที่ Data Engineer และ Data Scientist ควรรู้จัก

สวัสดีค่ะ เราชื่อแก้ว ปัจจุบันเป็น Data Engineering Team Lead ที่ LINE MAN Wongnai (LMWN) ในบทความนี้เราจะพูดถึง data stack ที่เราใช้ใน LMWN กัน เผื่อเพื่อนๆ ที่สนใจจะได้เห็นภาพแพลตฟอร์มและเครื่องมือทางด้าน data มากขึ้นค่ะ
ภาพรวมของ Data Stack ที่ใช้ในปี 2022
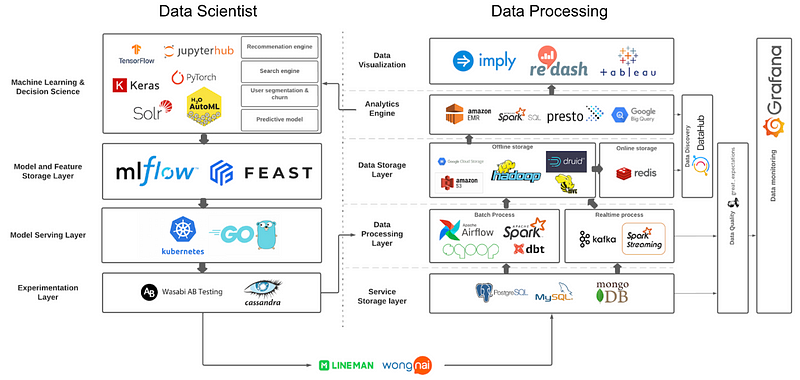
ด้านบนเป็นภาพรวมของเครื่องมือที่เราใช้ทั้งหมดใน data platform ของเราค่ะ จะเห็นว่าเราใช้ค่อนข้างเยอะ เบื้องต้น data platform ของเราอยู่บนโครงสร้างพื้นฐานของเซิร์ฟเวอร์ Verda ของบริษัท LINE Corporation (เป็น private cloud ของ LINE Corp) ที่พัฒนามาจาก OpenStack อีกทีหนึ่ง แต่จะเห็นว่าเราก็มีใช้บริการบางตัวของ public cloud อย่าง AWS และ GCP ด้วยเหมือนกัน
ด้านขวาเป็นส่วนของที่เราทำ data processing จัดการและเตรียม data ให้พร้อมสำหรับส่งต่อให้คนในบริษัทใช้ การจัดการ data ที่นี่ใช้ Hadoop และซอฟต์แวร์โอเพนซอร์สเป็นหลักค่ะ ส่วนทางด้ายซ้ายเป็น เครื่องมือที่เราเตรียมไว้ให้ data scientist ใช้งานและใช้สำหรับการ productionize model
ต่อไปเราจะอธิบายแต่ละส่วน และเครื่องมือแต่ละตัวว่าเราใช้งานยังไงบ้างค่ะ
Data storage

อันดับแรกขอเริ่มที่ data storage ที่เราใช้กันก่อนเลย ในส่วนของ services storage แบ่งเป็น service ของ Wongnai และ LINE MAN โดยฝั่ง Wongnai ใช้ AWS Aurora ที่เป็น MySQL และ PostgreSQL ซึ่งเป็น relational database ส่วนฝั่ง LINE MAN ใช้ MongoDB เก็บข้อมูล unstructured data ทำให้เราเจอ complex type บ่อยๆ จาก MongoDB ค่ะ
ในส่วนของ offline storage เราใช้เก็บข้อมูลที่ผ่านการ process แล้วเพื่อใช้สำหรับการทำ analytic เป็นหลักค่ะ อย่างที่กล่าวไปตั้งแต่ต้นว่าเราใช้ Hadoop Ecosystem เป็นหลัก เราจึงใช้ HDFS เป็น data lake และ Hive เป็น data warehouse นอกจากนี้เรายังมีการใช้ Apache Druid เป็น real-time analytics database ซึ่งสามารถ aggregation สำหรับ analytic ได้รวดเร็วมาก
ส่วน Google Cloud Storage (GCS) กับ Amazon S3 เราใช้แลกเปลี่ยน data กับ external party ค่ะ เช่น เรามี import ข้อมูลของ marketing กับ 3rd party tool เราจะให้ข้างนอกเข้ามาวางไฟล์ไว้ที่ GCS หรือเราต้อง export ข้อมูลให้กับพาร์ทเนอร์ก็จะวางไฟล์ไว้ที่ S3 ให้เขามาเอาข้อมูลไปใช้ต่อค่ะ
ในส่วนของ online storage ตอนนี้เราใช้สำหรับ ML serving กับใช้เก็บข้อมูลของ data product ที่ต้องการใช้ข้อมูลแบบเรียลไทม์ค่ะ ซึ่งแน่นอนว่าเราใช้ Redis ที่ขึ้นชื่อเรื่องความเร็วในการอ่านเขียนข้อมูลอยู่แล้ว
Data Processing

ในส่วนของการ process ข้อมูล จะแบ่งเป็นการประมวลผลแบบ batch และ realtime ค่ะ
สำหรับการประมวลผลแบบ batch เราใช้ Apache Sqoop ในการดึงข้อมูลจาก relational database และใช้ Apache Spark ดึงข้อมูลจาก MongoDB นอกจากนี้เรายังใช้ Spark และ dbt ในการ transform ข้อมูลให้อยู่ในรูปแบบที่นำไปทำ analytic ต่อได้ด้วย ในส่วนของ data orchestration เราใช้ Apache Airflow ที่ทำให้เราสามารถตั้ง schedule ในการดึงและ process data และควบคุม data pipeline ได้ง่ายด้วย ปัจจุบันเรามี data pipeline รันอยู่มากกว่า 200 อันแล้วค่ะ
สำหรับแบบ realtime เราใช้ Apache Kafka เป็น message queue เก็บ changelog จาก MongoDB แล้วใช้ Spark Streaming ไปดึง event message จาก Kafka ออกมาแล้ว transform ต่อค่ะ
Data Analytics & Visualization

มาดูในส่วนของเครื่องมือสำหรับผู้ใช้ data กันบ้างค่ะ ส่วนนี้ ผู้ใช้หลักของเรา คือ data scientist และ business intelligence (BI) analyst จะมา query ข้อมูลเพื่อนำไปวิเคราะห์หา insight ให้กับหน่วยธุรกิจต่างๆ
ส่วนของ analytic engine ที่เราใช้หลักๆ เป็น Presto ซึ่งเป็น distributed query engine ที่สามารถดึงข้อมูลขนาดใหญ่จาก Hive ได้อย่างรวดเร็ว โดยมี syntax การเขียนคล้ายกับ SQL นอกจากนี้เรายังมีใช้ Google BigQuery ทั้งในการเก็บข้อมูล behavior และทำ analytic บนนี้แบบเร็วๆ ด้วย ส่วน data scientist ที่ต้องใช้เครื่องแรงๆ ในการทำ machine learning ก็จะไปใช้ Amazon EMR ค่ะ
ส่วนของ visualization ที่นี่ใช้ Redash เป็นหลักค่ะ Redash เป็นซอฟต์แวร์ที่ทำได้ทั้งเขียน query เพื่อดึงข้อมูลและทำแดชบอร์ดจาก query ที่เขียนได้ด้วยค่ะ นอกจาก Redash แล้วเรายังนำ Imply ที่ต่อกับ Druid ทำ visualization แบบ aggregation ได้อย่างรวดเร็ว Imply เป็นเหมือน data mart และเป็น self-service BI tool ที่ผู้ใช้สามารถทำแดชบอร์ดด้วยตัวเองได้ง่ายมากค่ะ และตอนนี้เราก็เริ่มนำ Tableau มาใช้ทำ advance visualization ในบางทีมค่ะ
Data Quality & Discovery & Monitoring

ในหัวข้อนี้ขอพูดรวม 3 หัวข้อเลยค่ะ เป็นเรื่องที่ทางทีม data engineering เริ่มทำกันมาตั้งแต่ปีที่แล้วค่ะ
เรื่องแรกเลยคือเรื่องของ data quality เนื่องจากที่ LMWN ใช้ข้อมูลในการวิเคราะห์งานด้าน operation และ finance ของบริษัทด้วย ความถูกต้องของข้อมูลจึงมีความสำคัญมาก
ส่วนนี้เราเลือกใช้ great_expectations ที่สร้างขึ้นมาเพื่อ validate data โดยเฉพาะ สามารถ integrate เข้ากับ data pipeline ใน Airflow ด้วยค่ะ
ส่วนของ data discovery หรือ data observability เราเลือกใช้ DataHub ที่พัฒนาโดย LinkedIn มาใช้เก็บ data catalog, data lineage และ metadata อื่นๆ เราสามารถ ingest ข้อมูลจาก Airflow, dbt และ great_expectations เข้ามาเก็บไว้ใน DataHub ได้ด้วย ตัว DataHub เป็นส่วนที่เราเริ่มใช้งานอย่างจริงจังในปีนี้ เป็น work in progress ของทีมเราค่ะ
สุดท้ายคือส่วนของ monitoring ค่ะ การมอนิเตอร์ทำให้เรารู้ว่าสภาพของ data platform เป็นแบบไหนและสามารถบอกถึงปัญหาที่เกิดขึ้นในแพลตฟอร์มของเราได้ด้วย การมอนิเตอร์ส่วนใหญ่เราจะยิงเมทริคต่างๆ เข้า Prometheus ที่เป็น time-series database ที่ใช้สำหรับมอนิเตอร์โดยเฉพาะ แล้วให้ Grafana มาดึง เมทริคจาก Prometheus เพื่อเอามาแสดงผลเป็นแดชบอร์ด และแจ้งเตือนเมื่อมีสิ่งผิดปกติเกิดขึ้นในแพลตฟอร์มของเราค่ะ
จบด้านขวาที่เป็นส่วนของ data processing กันแล้ว ต่อไปเราจะมาดูเครื่องมือที่ data scientist ใช้กันค่ะ
Tools for Data Scientist

หลังจาก data scientist ดึงข้อมูลมาจาก data storage แล้วจะนำข้อมูลเหล่านั้นมาทำโมเดล ML ต่อค่ะ ที่นี่เราตั้ง JupyterHub ใช้ภายในบริษัทเอง ทำให้เราสามารถแชร์ notebook กันได้ค่ะ ส่วนไลบรารีที่ใช้ในการสร้างโมเดล ML เราไม่ได้ปิดกั้น แต่ส่วนใหญ่ใช้ TensorFlow และ Keras โดยมีการนำ H2O ที่เป็น AutoML มาช่วยทำ parameter tuning ด้วยค่ะ ส่วนของ search engine ใช้ Solr ซึ่งเป็นฐานข้อมูลสำหรับ search engine โดยเฉพาะ
ในระหว่างการพัฒนา ML model เรานำ MLflow มาใช้ในการเก็บ feature, ผลการทดลองและโมเดลในการพัฒนาแต่ละครั้ง ทำให้เรา keep track และเปรียบเทียบการจูน parameter ของโมเดลได้ นอกจากนั้น MLflow ยังสามารถใช้กับการทำ MLOps ซึ่งทีมเรากำลังเริ่มสร้าง MLOps Lifecycle กันด้วยค่ะ นอกจาก MLflow แล้ว เรายังนำ Feast ซึ่งเป็น feature store มาเก็บ feature ที่ใช้ทำโมเดลต่างด้วย จุดเด่นของ Feast คือเราสามารถใช้ API ในการดึง feature และสามารถทำ model serving ได้แบบเรียลไทม์ด้วยค่ะ
การทำ model serving ปัจจุบันเรา deploy model บน Kubernetes ภาษาหลักที่ใช้คือ Python กับ Golang แล้วแต่ว่าผลลัพธ์ของโมเดลไปออกที่ไหน บางทีถ้าเก็บไว้ในฐานข้อมูลก็สามารถใช้ Python ได้ แต่ถ้าต้องไปเชื่อมต่อกับตัวแอปของ LINE MAN หรือ Wongnai จะใช้ Golang ค่ะ
สุดท้ายเป็นการทำ A/B Testing เพื่อเปรียบเทียบผลลัพธ์ของผู้ใช้แบบออนไลน์ค่ะ ในส่วนนี้เราใช้ซอฟต์แวร์โอเพนซอร์สชื่อ Wasabi มาช่วยในการแบ่งกรุ๊ปของผู้ใช้ที่จะเจอโมเดลที่แตกต่างกัน โดยฐานข้อมูลที่ใช้เก็บ A/B experiment จะใช้ Cassandra ในการเก็บข้อมูล
ทั้งหมดนี้เป็นเครื่องมือที่เราใช้ใน data platform ของ LMWN ในปี 2022 ค่ะ หวังว่าเพื่อนๆจะได้เห็นภาพ data platform ของที่นี่มากขึ้นนะคะ
Co-writer : Jirawech Siwawut (Staff Data Scientist)

Leave a Reply