ถ้าพูดถึง Data Engineer ที่ LINE MAN Wongnai จะนึกถึงอะไรกันบ้าง
สวัสดีค่ะ เราชื่อแก้ว ปัจจุบันเป็น Data Engineering Team Lead ที่ LINE MAN Wongnai (LMWN) ค่ะ เราเริ่มทำงานที่นี่ในตำแหน่ง Senior Data Engineer ตั้งแต่เดือนก.ย. 2020 ตอนนี้เราก็ทำงานครบ 1 ปีแล้วค่ะ (เขียน ณ เดือนก.ย. 2021) เป็นเวลาที่เราจะเขียนบทความรีวิวชีวิตการทำงานของตัวเองเก็บไว้ พร้อมๆกับแชร์ประสบการณ์ให้กับคนอื่นๆที่สนใจอาชีพนี้ด้วย ต้องบอกก่อนว่าก่อนหน้านี้เราไม่ได้เป็น Data engineer นะคะ เราเป็น Data scientist มา 3 ปีค่ะ เป็นหนึ่งคนที่เพิ่งเปลี่ยนสายงานมาทำด้านนี้ค่ะ
บทความนี้จะแบ่งเป็น 3 ส่วนค่ะ (เผื่อใครไม่สนใจ part ไหนก็ข้ามๆไปเลย)
- งาน Data engineer ที่ LMWN ทำอะไรบ้าง (ใน part นี้จะมีคำศัพท์ทางเทคนิค skills และชื่อ tools ต่างๆที่ใช้ในงาน Data engineer ที่ LMWN ด้วยค่ะ)
- Challenge ของงาน Data engineer
- Culture การทำงานของ Data engineer ที่ LMWN
งาน Data Engineer ที่ LMWN ทำอะไรบ้าง
เกริ่นก่อนนิดนึง … เราเชื่อว่าคนส่วนใหญ่น่าจะรู้จัก LMWN ผ่านแอป LINE MAN และแอป Wongnai กันอยู่แล้ว เราถือว่า LMWN เป็นบริษัทขนาดกลางที่มีพนักงานประมาณ 1 พันคน เราสามารถพูดได้อย่างเต็มปากเลยว่า LMWN เป็น Data-driven organization ที่ทุกทีมในบริษัทใช้ data ในการตัดสินใจทางธุรกิจ (แม้แต่ทีม People ก็ยังมี Dashboard เป็นของตัวเอง!) เพราะฉะนั้น user ที่ใช้ data ของ LMWN จะไม่ใช่แค่ Data scientist (DS) หรือ Business Intelligence analyst (BI) เท่านั้น แต่ยังมีทีม Operations, Sales, Marketing, Strategy, PM, etc. ที่มาใช้ข้อมูลด้วย ไม่ว่าจะด้วยการเขียน SQL ด้วยตัวเอง หรือใช้ BI Tools ก็ตาม
ดังนั้น Data engineer (DE) จึงมีหน้าที่หลักๆ คือทำให้ทุกๆคนในบริษัทสามารถเข้าถึง data ได้และใช้ data ได้อย่างมีประสิทธิภาพมากที่สุดผ่าน Data platform ของเราค่ะ ซึ่งงานของ DE ที่เราและทีม DE ได้ทำกันมาในระยะเวลา 1 ปีก็มีดังนี้ค่ะ
ETL
แน่นอนว่าถ้าเราเป็น DE สิ่งที่เราต้องทำคือการทำ ETL (Extract, Transform, Load) ข้อมูลและสร้าง Data pipeline ได้ ซึ่งก็คือการดึงข้อมูลจาก data source ต่างๆ มาเก็บไว้ใน Data lake และเตรียมข้อมูลให้ user พร้อมใช้ใส่ใน Data warehouse ค่ะ ที่นี่เราจะมี Data pipeline ทั้ง 2 แบบ คือแบบ Batch และ Streaming ค่ะ
Batch pipeline
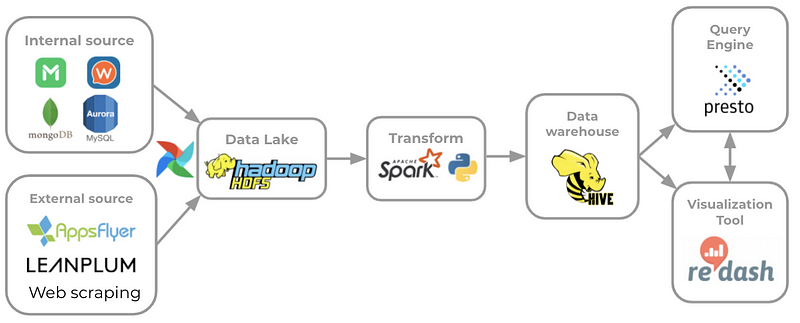
ก่อนอื่นขอบอกก่อนว่าการจัดการ data ที่ LMWN เราจะใช้ Hadoop framework และ Open-source tools เป็นหลักค่ะ การทำ Batch ETL ของเราก็จะใช้ Airflow เป็น ตัว Scheduler ในการดึงข้อมูลจากแหล่งต่างๆมามาเก็บไว้ใน HDFS ที่เป็น data lake แล้วใช้ Spark หรือ python ในการ transform ข้อมูลให้พร้อมใช้แล้ว Load เก็บไว้ใน Hive ที่เป็น Data warehouse ค่ะ จะเห็นว่า data source ที่เราดึงข้อมูลมาค่อนข้างหลากหลาย ไม่ได้มีแค่เพียงจาก Operational database ที่เป็น MongoDB (ฝั่ง LINE MAN) กับ AWS Aurora (ฝั่ง Wongnai) เท่านั้น แต่ยังมีการดึงข้อมูลจาก 3rd party tools หรือทำ Web scraping อีกด้วยค่ะ
งานหลักๆของเราก็คือทำ Data pipeline บน Airflow ตาม request ของ user ค่ะ สำหรับตัว Jobs ใน Airflow ก็จะมีทั้งที่เป็น weekly, daily และ hourly แล้วแต่ว่า user ต้องการใช้ข้อมูลอัพเดตเร็วแค่ไหน ถ้า user ต้องการข้อมูลจาก data source ข้างนอก เราก็ต้องเขียนโปรแกรมไปดึงข้อมูลจาก api ด้วย ส่วนใหญ่จะใช้ภาษา python ในการเขียนโปรแกรมค่ะ นอกจากนี้ ถ้า jobs รันนานเกินไป เราก็ยังมีหน้าที่ต้อง optimize jobs (โดยเฉพาะ spark) ให้รันเร็วขึ้นด้วยค่ะ
เนื่องจาก LINE MAN กับ Wongnai เพิ่ง merge กัน Data platform ของทั้ง 2 บริษัทยังมีบางส่วนที่แยกกันอยู่บ้าง ฝั่ง Wongnai ยังมี Data pipeline อยู่บน AWS ค่ะ เราก็ยังต้อง maintain และพัฒนา pipeline ของ Wongnai อยู่บ้าง ส่วน tools ที่ใช้ส่วนใหญ่บน AWS ก็จะมี S3, EMR, Glue ค่ะ
Streaming pipeline
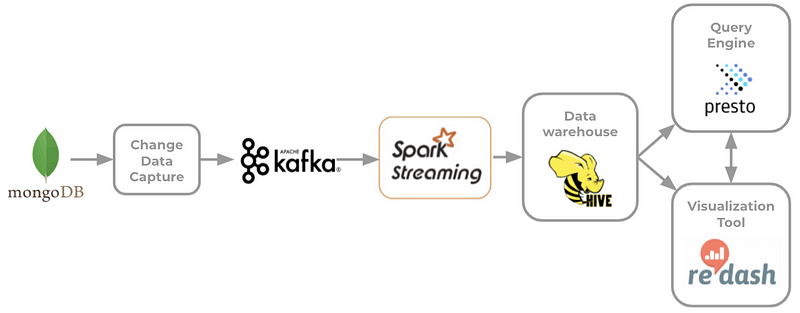
เนื่องจากทาง Operation ของ LINE MAN ต้องการข้อมูลเพื่อใช้ในการตัดสินใจแบบ Realtime ทีมเราจึงได้พัฒนา Streaming pipeline ขึ้นมาค่ะในปีนี้ค่ะ
การทำ Streaming pipeline จะเริ่มจากตัว Change Data Capture (CDC) ที่สามารถ detect การเปลี่ยนแปลงไม่ว่าจะเป็นการ insert, update, replace หรือ delete ของ Table ที่เราสนใจได้ทันที แล้วส่งเป็น event message เข้าไปใน Kafka ซึ่งเป็น Message queue ชนิดหนึ่งค่ะ จากนั้นเราก็จะใช้ Spark Streaming ไปดึง event message จาก Kafka มาแล้ว transform ให้อยู่ในรูปแบบ Table ที่สามารถนำใช้งานต่อได้แล้วเก็บไว้ใน Hive เหมือนกับ Batch pipeline ค่ะ
Streaming pipeline มีส่วนที่ต้องเขียนโปรแกรม 2 ส่วน คือ ส่วนที่เป็น CDC และ Spark Streaming ในส่วนของ CDC เราเลือกใช้ Change Streams ของ MongoDB ที่ต้องเขียน connector ขึ้นมา ส่วนนี้ได้รับความช่วยเหลือจากทีม SRE มาช่วยเขียน service ที่เป็น golang ให้ค่ะ ส่วน Spark streaming ทีม DE เป็นคนเขียนตัว transform ข้อมูลเอง เราเลือกใช้ Java ในส่วนนี้ค่ะ
จะเห็นได้ว่า ไม่ว่าจะเป็น Pipeline แบบ Batch หรือ Streaming ปลายทางของข้อมูลก็จะเป็น Hive เหมือนกัน โดย platform ของที่นี่จะให้ user query ข้อมูลจาก Hive ผ่าน Presto ที่เป็น Distributed SQL query engine ซึ่งตัว Presto จะ query ข้อมูลใหญ่ๆได้เร็วกว่า Hive มาก แล้วเราก็มี Redash เป็น Open-source visualization tools ที่สามารถเชื่อมต่อกับ Presto ได้ด้วย ทำให้ user สามารถเขียน query และทำ visualization ของข้อมูลขนาดใหญ่ได้อย่างรวดเร็วค่ะ
Data product
การเป็น DE ที่นี่ไม่ได้แค่ทำ ETL แค่อย่างเดียวค่ะ แต่เรายังมีส่วนพัฒนา Data products ของ LINE MAN และ Wongnai ด้วย เวลาที่ DS พัฒนา ML Model ออกมาแล้วอยากจะ deploy ขึ้นแอป LINE MAN หรือ Wongnai เราก็จะไปช่วย implement service ต่างๆที่จะช่วยให้ผลลัพธ์จาก ML model ออกไปสู่แอปได้
พอ DS ทำ ML Model เสร็จ ทั้ง DE และ DS ต้องมา design architecture (ปรึกษาทีม Architect) และออกแบบ service ที่จะต้อง implement เพิ่มกันก่อน และดู backward compatible ด้วยว่าการเอา Model ขึ้นไปรันบนแอปจริงๆนั้น จะไม่ทำให้ functionality ของแอปที่มีอยู่พังไปด้วย
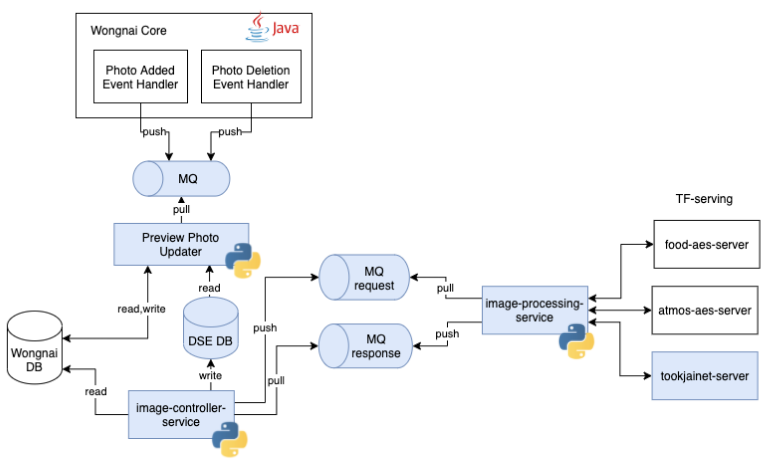
ในรูปเป็นตัวอย่างโปรเจคหนึ่งที่ทำร่วมกันกับ DS ค่ะ สีฟ้าในรูปคือสิ่งที่จะต้อง implement เพิ่มค่ะ จริงๆแล้ว DS เพียงแค่ทำโมเดลรูปตัวใหม่ออกมาเท่านั้น แต่การที่จะทำให้โมเดลรูปตัวใหม่สามารถทำงานได้บนแอปนั้น จะเห็นว่ามี service ที่ต้อง implement เพิ่มหลาย service เลยทีเดียว ซึ่งตรงนี้จะเป็นหน้าที่ของ DE ที่จะเข้ามาช่วย implement service เหล่านี้ให้ค่ะ
ส่วนใหญ่ถ้า service ไม่ได้รับโหลดมากก็สามารถใช้ python ได้ค่ะ แต่ถ้ารับโหลดมากและต้องการ latency ต่ำ ก็จะไปใช้ golang แทน ในส่วนของ deployment service ก็ต้องมีความรู้เรื่อง Docker และ Kubernetes เบื้องต้นด้วยค่ะ
หากจากสนใจรายละเอียดในการทำ Data product กับ DS ก็สามารถอ่านเพิ่มได้ที่บทความ กว่าจะออกมาเป็น Data Product … ทีม Data ต้องทำอะไรกันบ้าง
Data support
อันนี้ถือเป็น day-to-day work ของ DE เลยก็ได้ค่ะ คือการทำ Data support เมื่อมีปัญหาทางด้าน data เข้ามาจาก user ทีมต่างๆ ส่วนใหญ่จะเป็นช่วงเช้าวันจันทร์อังคารที่แต่ละทีมจะมี weekly meeting แล้วต้องเปิด dashboard กันเยอะ ซึ่งปัญหาที่เจอก็จะมีหลากหลาย บางทีก็
- Data ไม่ update บ้าง
- Data duplicate บ้าง
- Check data 2 ที่แล้วไม่เท่ากัน
- Run query ไม่ออก
- เพิ่ม column ใน table ให้หน่อย
- และอื่นๆอีกมากมาย
ซึ่งจริงๆแล้วปัญหาเหล่านี้ก็เป็นสิ่งที่เราต้องทำ Improvement บน Data platform ของเราซึ่งจะพูดถึงในหัวข้อถัดไปค่ะ
ในการจัดการปัญหาทางด้าน data เราจะมี slack channel ชื่อ #help-data อยู่ ซึ่งใน channel นี้ทุกคนสามารถ submit form ทาง workflow ของ slack ได้เพื่อแจ้งปัญหาให้ทางทีมรับรู้ แล้วทีมก็จะ assign DE ให้ไปช่วยแก้ปัญหาให้เร็วที่สุดค่ะ
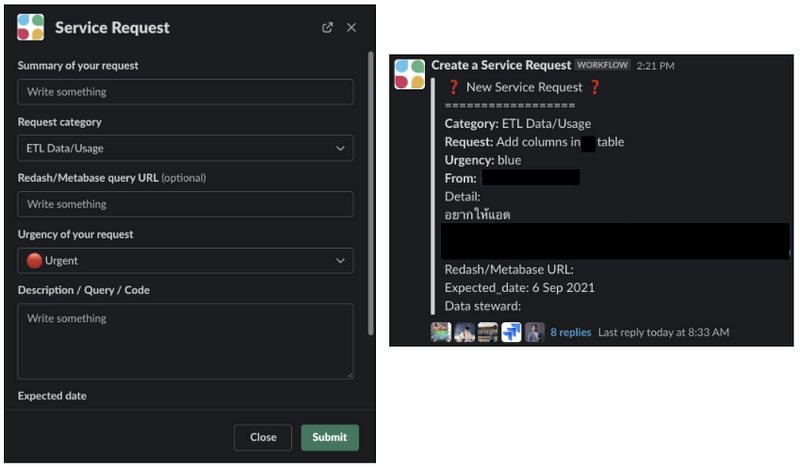
Data platform monitoring and improvement
สืบเนื่องจากปัญหาที่เข้ามาใน slack channel #help-data จึงทำให้เรารู้ว่า data platform ของเราเองยังคงต้องมีการพัฒนาอีกเยอะ ทีมเราก็อยากให้มีความผิดพลาดน้อยลง อยากให้มีจำนวนเคสที่ submit มาน้อยลง DE จึงยังมีหน้าที่จะคอยทำ monitoring และ improve data platform ให้ดีขึ้นด้วยค่ะ
การทำ Monitoring จะทำให้เรารู้ว่าสภาพของ data platform เราเป็นแบบไหนและสามารถบอกถึงปัญหาที่เกิดขึ้นใน platform ของเราได้ด้วยค่ะ โดยการทำ Monitoring ส่วนใหญ่เราจะยิง metrics ต่างๆเข้า Prometheus (Time-series database ที่ใช้สำหรับ monitoring) แล้วให้ Grafana มาดึง metric จาก Prometheus เพื่อเอามาแสดงผลเป็น dashboard และแจ้ง alert เมื่อมีสิ่งผิดปกติเกิดขึ้นใน platform ของเราค่ะ
ตัวอย่าง Monitoring ที่ทีมทำก็เช่น
- Data quality monitoring ใช้ดูว่า table ที่สำคัญๆอัพเดตได้ตรงตามเวลาไหม
- Airflow monitoring ใช้ดู metric ต่างๆของ airflow, ดูว่าแต่ละ Job ใช้เวลาเท่าไหร่, airflow ทำงานปกติไหม
- Redash/Presto monitoring ใช้ดูว่ามีคนกำลัง query อยู่เท่าไหร่ มี query เยอะผิดปกติหรือเปล่า
- Stream monitoring ใช้ดูว่า streaming pipeline ใช้ resource เท่าไหร่ แต่ละ batch latency เกินจนทำให้ data มาช้าหรือเปล่า
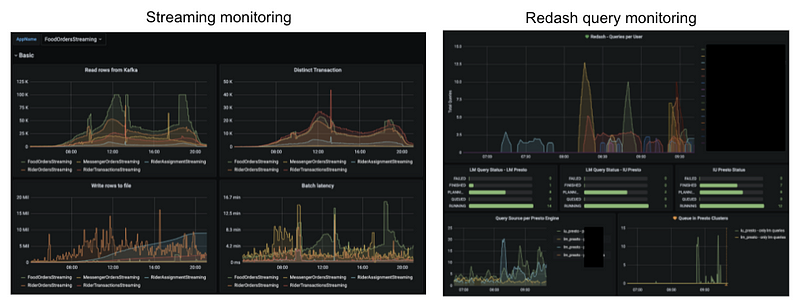
ส่วนการทำ improvement ของ data platform ก็มีหลายส่วน เช่น
- พัฒนา library ที่ใช้กับ airflow ให้มี functionality มากขึ้น (ที่นี่จะมี in-house library ที่ใช้กับ airflow โดยเฉพาะค่ะ)
- เพิ่ม resource (เครื่อง) ให้กับ presto เพื่อที่จะได้รองรับ query ได้มากขึ้น
- ปรับจูน spark parameter ให้ spark job รันเร็วขึ้น
นอกจากนี้ DE ยังมีหน้าที่หาและทดลอง Tools ใหม่ๆมาเติมเต็มให้กับ data platform ด้วยค่ะ ตัวอย่างที่เราเคยทำก็คือทดลองหา Data catalog หรือ Metadata platform ที่จะมาเก็บข้อมูล metadata ค่ะ ก็ต้องดูว่าต้องใช้ Infrastructure อะไรบ้าง (ตรงนี้จะทำงานร่วมกับ SRE และ Architect) แล้วก็ทดสอบ functionality ด้วยค่ะ ว่าแต่ละ tools ตอบโจทย์กับสิ่งที่เราต้องการหรือเปล่า
Challenge ของงาน Data Engineer
หลังจากทำงานมาได้ 1 ปี เราได้เจอ challenge มากมาย ด้วยความที่ย้ายสายงานมาด้วย ทุกสิ่งทุกอย่างก็ใหม่มากเลยสำหรับเราในปีนี้ เราขอสรุป challenge ที่เราเจอเป็นหัวข้อตามนี้ค่ะ
- เป็น DE ต้องติดตามเทคโนโลยีใหม่ๆตลอดเวลา : เนื่องจากงานของ DE ที่นี่ค่อนข้างกว้างค่ะ ไม่ได้แค่ทำ ETL เพียงอย่างเดียว แต่ต้องดู platform ด้วย ทำให้เราต้องติดตามเทคโนโลยีและ tools ใหม่ๆอยู่เสมอ ถ้ามีอะไรที่อัพเดตแล้วสามารถนำมาพัฒนา platform ของเราได้ ก็เป็นโอกาสที่เราจะนำ tools นั้นมาเติมเต็มให้กับ platform ของเราค่ะ
- มี Tools ให้เลือกเยอะ ต้องเลือกให้เหมาะสมกับการใช้งาน : ในโลกของ data มี tools ที่มี function ที่เหมือนกันเยอะ แต่อย่างที่อธิบายไปใน part ของ data platform ค่ะว่าการจะเลือก tools เข้ามาใน platform ก็ต้องดู component ต่างๆว่าใช้กับ infrastructure ที่เรามีอยู่ได้ไหม หรือว่าต้องตั้งขึ้นมาใหม่ เช็ค function ที่เราต้องการใช้ว่าครบถ้วนไหม และสุดท้ายคือ ease of use ค่ะ ดูว่าใช้งานได้ง่าย integrate กับ platform ที่เรามีอยู่ได้ง่ายหรือไม่
- Challenge ของ data platform : ทำยังไงให้ user เข้าถึง data ได้ง่าย รวดเร็ว ซึ่งตัว platform ก็จะมี challenge อีกมากมาย เช่น
- Data availability and freshness : ทำยังไงให้ data pipeline ไม่พัง พังทีนึงกระทบกับ user ทั้งบริษัท ทำยังไงให้ data อัพเดตตามเวลาที่ user ต้องการใช้ (เช่น ถ้าเป็น realtime data ก็ต้องอัพเดตภายใน 10 นาที)
- Data reliability : ทำยังไงให้ data มีความถูกต้อง ไม่มี data loss หรือ data duplication
- Data platform scalability : ทำยังไงให้ user สามารถ query พร้อมๆกัน ได้เป็นร้อยๆ query โดยที่ user ไม่ต้องรอนาน ยิ่งช่วงวันจันทร์อังคารที่ทุกคนพร้อมใจกันเปิด dashboard ใน meeting นี่ dashboard หมุนติ้วๆไม่หยุดเลย
- Data observability : ทำยังไงให้ user รู้ว่ามีข้อมูลอะไรอยู่ตรงไหนบ้าง จะได้ใช้ข้อมูลที่มีให้เกิดประโยชน์สูงสุด
- และอื่นๆอีกมากมายที่ยังคงต้องพัฒนา data platform ต่อไป …
Culture การทำงานที่ LMWN
ในปีที่ผ่านมา DE จะอยู่ในทีม Data Science and Engineering (DSE) ซึ่งประกอบไปด้วย DE และ DS เราค่อนข้างทำงานใกล้ชิดกับ DS และมีการ sync งานที่ทำกันตลอดเวลาค่ะ
ลักษณะของทีมเราเรียกได้ว่าเป็นทีมที่มี Talent density สูงค่ะ ทุกคนมีความเก่งที่ทำให้เราอยากจะพัฒนาตัวเองให้เก่งตามไปด้วย และทีมนี้มีความเป็น Teamwork & support สูงมาก เวลาใครมีปัญหาอะไรก็จะช่วยกันแก้ไข ช่วยกัน brainstorm วิธีการแก้ปัญหาให้การทำงานราบรื่นค่ะ
วิธีการทำงานของเราก็จะใช้ระบบ Agile โดยแบ่งการทำงานเป็น sprint ละ 2 อาทิตย์ โดยใช้ JIRA เป็น tool จัดการงานใน sprint แล้วก็มีกิจกรรมต่างๆดังนี้ค่ะ
Standup Meeting
ทุกวัน 10:30am เราจะรวมตัวกันเพื่ออัพเดตงานที่ทำ ดูว่าทุกคนมีปัญหาในตัวงานที่ทำอยู่หรือเปล่า ถ้ามีปัญหาหรือ blocker ใครจะช่วยอะไรได้บ้างไหม บางทีหลังจากที่ทุกคนอัพเดตงานเสร็จแล้วก็จะมีการปล่อยของกันเล็กๆน้อยๆ เช่น งานที่ทำมาใน sprint ที่แล้วหรือบางที DS เจอ insight อะไรน่าสนใจก็จะมีการแชร์กันในช่วงนี้ด้วยค่ะ (ช่วง WFH บางวันก็จะมีคุยเล่นลากยาวไปถึงเกือบเที่ยงก็มีค่ะ)
Sprint grooming
เป็น session ที่เราจะมาไล่ดู task ใน backlog ว่าแต่ละการ์ดมี requirement ชัดเจนหรือยังและมีการจัดเรียง priority ของแต่ละ task ด้วยค่ะ
Sprint planning
เป็นช่วงเวลาปิด sprint ก็จะมีการรีวิวว่ามี task ที่ยังไม่เสร็จไหม ถ้ายังไม่เสร็จก็ต้องอธิบายว่าทำไมถึงไม่เสร็จ มีอะไรเป็น blocker อยู่ แล้วก็เป็นช่วงที่จะวางแผนว่า sprint ถัดไปจะทำอะไรค่ะ
Retrospective
session นี้เป็น session ที่เราชอบมากเลยค่ะและก็อยากจะพูดถึงมันเป็นพิเศษด้วย Retrospective ของที่นี่จะทำทุกๆ 1 เดือน และจะมี 2 ส่วน
- ส่วนแรกคือส่วนของ Health Check คือให้แต่ละคนให้คะแนนตัวเองในด้านต่างๆ แล้วก็มาอธิบายว่าทำไมถึงให้คะแนนเท่านั้น ถ้าทุกคนยังให้คะแนนตัวเองดีก็ดีไป แต่ถ้ามีคนในทีมให้คะแนนตัวเองน้อย ทีมก็จะรับรู้ว่าคนๆนี้กำลังเจอกับปัญหาอะไรอยู่ และจะถามว่าเราจะช่วยเขายังไงได้บ้าง
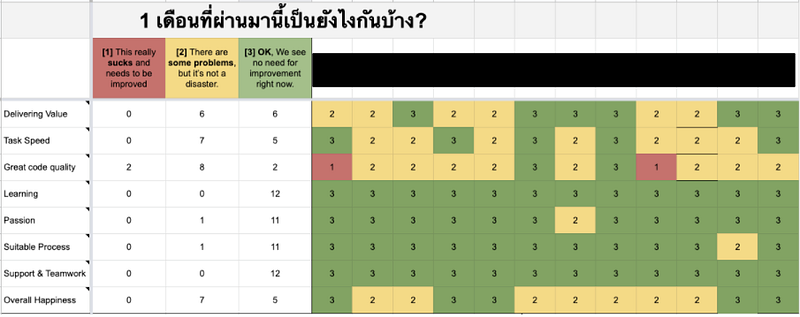
- อีกส่วนคือส่วนที่มา Review กันว่า What went well และ What needs to be improved ค่ะ ตรง What went well เราก็จะเขียนว่าทำอะไรได้ดีบ้าง และเป็นพื้นที่ของการโชว์ appreciation, recognition ขอบคุณคนในทีมที่มาช่วยทำให้งานสำเร็จ ส่วนตรง What needs to be improved ก็คือปัญหาที่แต่ละคนในทีมมองเห็นแล้วลิสออกมา
สิ่งที่ชอบคือทุกปัญหาที่อยู่ในนี้ ทีมจะ brainstorm ถึงวิธีการแก้ปัญหา “ทุกอัน” ไม่มีการเลือกว่าแก้อันไหนก่อน ทุกอันคือปัญหา ทุกปัญหาต้องมี solution ถ้ามีสิ่งที่ต้องเป็น task ก็สร้างการ์ดเข้า backlog ไปเลย ถ้าต้องมีคนรับผิดชอบก็ assign คนรับผิดชอบไปเลย
เราชอบเพราะเรารู้สึกว่ากิจกรรมนี้ทำให้ “ทีม” มี Recognition และมี Improvement ตลอดเวลา ทำให้เรามองเห็นคนในทีมมากขึ้นและทำให้ทีมเป็นทีมที่ดีขึ้นค่ะ
Knowledge sharing
แน่นอนว่าเป็น session ที่ขาดไม่ได้สำหรับการทำงานสาย data เลย ด้วยความที่เทคโนโลยีเปลี่ยนแปลงเร็วและตัวงานของ DE และ DS มีความหลากหลายมาก ทีมเราก็เลยมีการทำ Knowledge sharing อยู่เรื่อยๆค่ะ ไม่ว่าจะเป็น Mini sharing หลัง Standup meeting หรือจะเป็นการมาแชร์งานที่ตัวเองทำเพื่อ Brainstorm idea จากคนอื่น รวมไปถึงการแชร์เทคโนโลยีใหม่ๆ หรือหัวข้อต่างๆที่เกี่ยวกับงาน data แต่ละ session จะมีการอัดวีดีโอเก็บไว้ให้ดูย้อนหลังกันด้วย ทีมนี้มีแต่คนปล่อยของเต็มไปหมดค่ะ เรียกได้ว่าอยู่ทีมนี้มีแต่ได้ความรู้แน่นอน
จบแล้วค่ะ สิ่งที่เราได้เรียนรู้ตลอด 1 ปีที่ผ่านมาที่ LMWN เราหวังว่าบทความนี้จะทำให้คนที่สนใจงาน DE เห็นภาพมากขึ้นว่า DE ที่ LMWN ทำอะไรบ้าง ใช้เทคโนโลยีอะไรบ้าง มีลักษณะการทำงานเป็นยังไง

Leave a Reply