How I grow with FINNOMENA
สวัสดีคนที่หลงเข้ามาในบทความของเราอีกแล้ว ผ่านมาเกือบ 2 ปีครึ่งแล้ว (10 Jan 2020) กับการหลงเข้ามาเป็น Data Scientist ที่ FINNOMENA
ในโอกาสที่บริษัทระดมทุน Series B ได้สำเร็จ เราก็เลยอยากจะเขียนอัพเดตประสบการณ์การทำงานและบทบาทของ Data Scientist ใน Startup เล็กๆแห่งนี้ที่โตขึ้นมาอยู่ใน Series B เก็บไว้ค่ะ
โดยบทความนี้เราอยากจะเล่าตัวอย่างการทำงานของ Data Scientist แบบ End-to-end หรือที่เขาชอบเรียกกันว่า Full-Stack Data Scientist ในบริษัทนี้ให้ฟังกันค่ะ (จริงๆมันก็คือ Data GB หรือ Data Scientist ที่ต้องทำทุกอย่างนั่นแหละ)
บทความนี้แบ่งเป็น 2 ส่วนค่ะ
- Data Team @FINNOMENA : เล่าการเติบโตของทีม Data ใน Startup เล่าว่าเราทำอะไรกันบ้าง (ไม่สนใจปัดข้ามไปได้ค่ะ)
- การทำงานแบบ Full-Stack Data Scientist ใน FINNOMENA รวมถึงบอก Skill ที่ใช้ในการทำงานตอนนี้ด้วยค่ะ
Disclaimer : บทความนี้เขียนจากประสบการณ์ส่วนตัวของเราเอง Data Scientist ที่อื่นอาจจะมีบทบาทที่แตกต่างกันค่ะ
Disclaimer2 : ปัจจุบันผู้เขียนไม่ได้ทำงานที่ FINNOMENA แล้วนะคะ ข้อมูลอาจมีการเปลี่ยนแปลงได้ค่ะ
หากใครยังไม่เคยอ่านบทความปีที่แล้ว ก็ไปอ่านกันได้ที่ ประสบการณ์ 1 ปีกับการเป็น Data Scientist ที่ Startup แห่งหนึ่งย่านสีลม

Data Team @FINNOMENA
ก่อนจะไปพูดถึง Full-Stack Data Scientist ขอเล่าความเป็นมาของทีม Data ใน FINNOMENA ให้เห็นภาพการทำงานของเรานิดนึงก่อนค่ะ
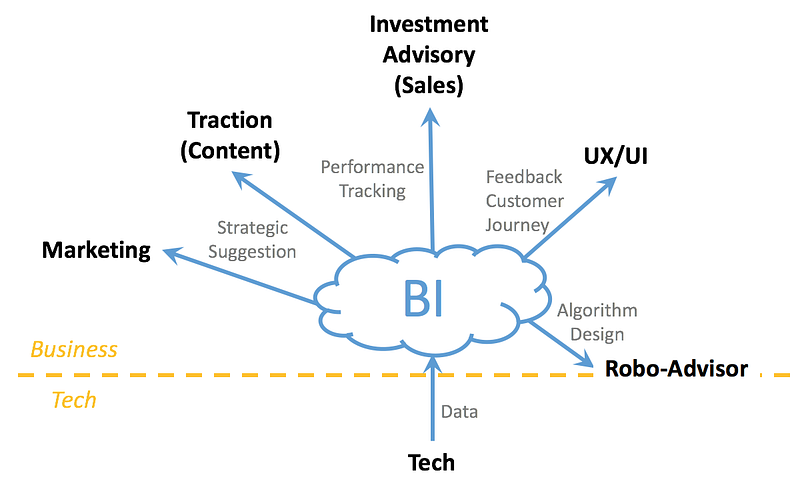
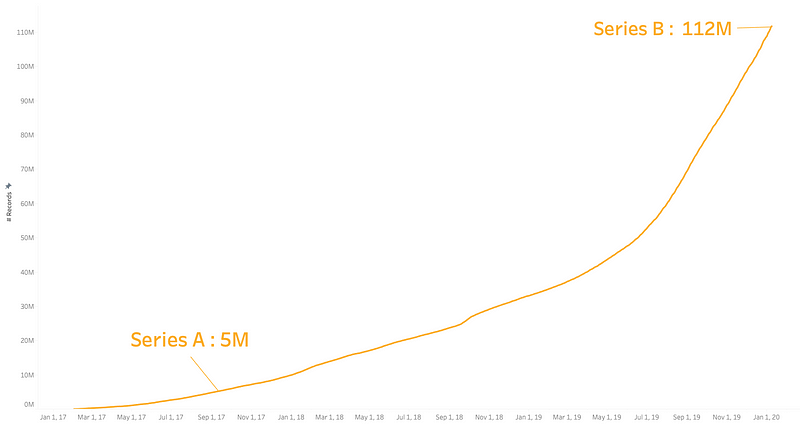
ตอนแรกที่เราเข้ามา (ปี 2017) บริษัทเพิ่งจะได้ Series A มีพนักงานอยู่แค่ประมาณ 20–30 คนเท่านั้น ทีมเราตอนแรกชื่อทีม Business Intelligence (BI) ซึ่งขอบเขตงานของ BI ก็จะแค่ทำ Dashboard มอนิเตอร์ตัวเลขต่างๆ, วิเคราะห์ข้อมูลเพื่อหา Insight และให้คำแนะนำประกอบการตัดสินใจให้ทีมอื่น ซึ่งส่วนใหญ่ก็จะเป็นทีม Marketing กับทีม Traction (Content) โดยใช้ข้อมูลเล็กๆ ประมาณ 5 ล้าน record เท่านั้น
2 ปีจาก Series A มาเป็น Series B มีอะไรเปลี่ยนแปลงเยอะเลยค่ะ บริษัทเราโตขึ้นมาก (ตอนนี้ก็ร้อยคนแล้ว) มีทีมเพิ่มขึ้นและมีจำนวน Product มากขึ้น มีระบบซื้อขายกองทุนของตัวเอง มีช่องทางการสื่อสารกับลูกค้ามากขึ้น ทำให้มีลูกค้าเข้ามาใช้ Platform ของเรามากขึ้น ตามมาด้วยระบบจัดการข้อมูลลูกค้าที่ซับซ้อนมากขึ้น

จากการเติบโตของบริษัททุกภาคส่วนนี้ สิ่งที่ตามมาก็คือ เรามีข้อมูลให้ทำ Analytic เพิ่มขึ้นแบบมากมายจากทุก Platform และทุกช่องทาง ยิ่งไปกว่านั้นทุกทีมต้องการข้อมูลไปซัพพอร์ตค่ะ!
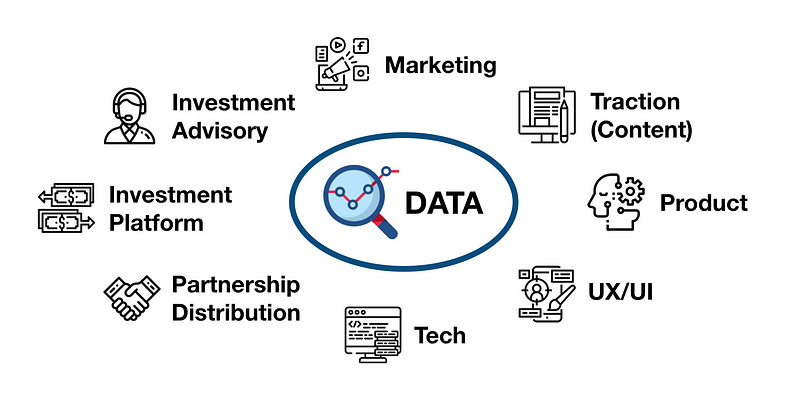
เพื่อให้เรามีข้อมูลเพียงพอไปซัพพอร์ตทีมอื่นๆ และทำการวิเคราะห์ข้อมูลได้ลึกมากขึ้น Scope งานของเราเลยเริ่มขยาย จากแค่เอาข้อมูลเล็กๆมาวิเคราะห์ ก็รวมไปถึงการดึงข้อมูลจาก Platform อื่นๆและการจัดการข้อมูลที่เพิ่มขึ้นมาอย่างมากมายให้อยู่ในรูปแบบที่นำไปใช้งานได้ งานของเราเลยเป็นการทำ Data แบบ End-to-end เลย ซึ่งคร่าวๆก็มีดังนี้
- Data Collection : กำหนดการเก็บ Data ของ Product ที่ออกใหม่และรวมไปถึงการดึงข้อมูลมาเก็บจาก Platform อื่นมาที่ Data Lake ของเรา
- Data Integration & Preparation : การรวบรวมข้อมูลจากแหล่งต่างๆ ออกแบบ Data pipeline และทำ ETL เพื่อให้ได้ข้อมูลพร้อมใช้สำหรับการวิเคราะห์
- Data Analytic & Modeling : วิเคราะห์ข้อมูลและทำ Predictive Model
- Data Visualization : ทำ Report ผลการวิเคราะห์ข้อมูลและทำ Dashboard เพื่อมอนิเตอร์ Metrics ต่างๆที่สำคัญของแต่ละทีม
- Model Deployment : ทำโมเดลเสร็จแล้วก็ต้องเอาไปรันจริง ใช้งานจริงด้วย
ด้วยตัวงานของทีมที่เปลี่ยนไปอย่างมากมายตอนนี้ทีมเราเลยเปลี่ยนชื่อจาก Business Intelligence เป็น Data ไปแล้ว
ถึงแม้งานจะเพิ่มขึ้นมากแค่ไหน แต่เรื่องจำนวนสมาชิกในทีมเนี่ย … ตอนปีที่แล้วที่เขียนบทความทีมมี 4 คน ตอนนี้ทีมก็ยังมี 4 คนเหมือนเดิมค่ะ 555 (ในเลขห้ามีน้ำตาซ่อนอยู่ T-T)

การทำงานแบบ Full-Stack Data Scientist
ถ้าพูดถึง Data Scientist ทุกคนคงจะนึกถึงการทำโมเดลด้วย Machine Learning หรือ Deep Learning หรือ นั่งทำ AI แบบคูลๆ
แต่ … ตื่นก่อนค่ะ
มันไม่ใช่ว่า Data Scientist ทุกคนจะได้ทำแบบนั้นค่ะ โดยเฉพาะในบริษัท Startup แบบเรา และจริงๆการทำโปรเจค Data Science ก็ไม่ได้มีแค่การทำโมเดลเท่านั้น ยังมีส่วนงานอื่นที่สำคัญกว่าการทำโมเดล โดยขั้นตอนการทำโปรเจค Data Science สามารถสรุปได้ตามรูปด้านล่างค่ะ
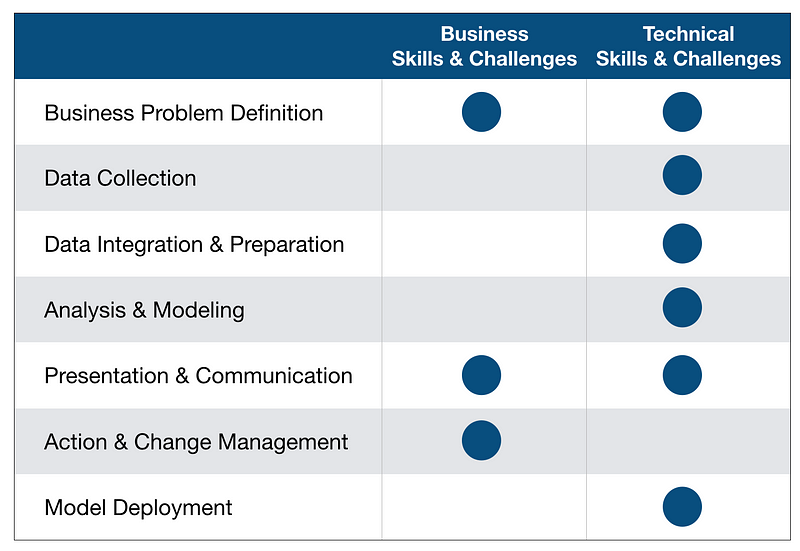
Data Science เองถือเป็นสหสาขาวิชาชีพ (Multi-disciplinary) อยู่แล้ว แต่การที่เราจะสามารถทำให้ครบขั้นตอนด้านบนได้นั้น เราจะต้องมีความรู้แบบ T-shaped คือรู้ลึกอย่างเดียวไม่ได้ แต่ต้องรู้กว้างด้วย ซึ่ง Forbes เขียนไว้ว่าคนที่เป็น Full-stack Data Scientist เนี่ยต้องเป็นการ Fusion ของ 3 คนรวมกัน คือ
- Decision Scientists : คนที่เข้าใจปัญหาทาง Business และเอาความรู้ทางด้าน Data Science ไปประยุกต์ใช้ได้
- Data Scientists : คนที่เข้าวิธีการจัดการกับข้อมูลและอัลกอริทึมต่างๆ
- Machine Learning Engineer : คนที่ทำ Data pipeline และ ML บน Production ได้
ดังนั้น จะเห็นว่าในตารางข้างบนเราแบ่ง Skills & Challenges ในการทำงานออกเป็นฝั่ง Business และ Technical เพราะจริงๆ Data Scientist ไม่ได้นั่งเขียนโปรแกรมทำโมเดลอย่างเดียว แต่เราต้องรู้และทำงานด้าน Business ด้วยค่ะ
มาๆ เราจะเล่าให้ฟังว่าเราเจออะไรมาบ้างในแต่ละ Process ด้านบน
Business Problem Definition
การกำหนดปัญหาเป็นขั้นตอนแรกและขั้นตอนที่สำคัญที่สุดของการทำโปรเจค Data Science
จริงๆก็มีหลายบทความเขียนไว้ และอย่างที่เราเคยบอกในตอนที่แล้ว งานของเราจะมี Value ก็ต่อเมื่อเรามองเห็นปัญหาและแก้ปัญหาให้กับธุรกิจของเราได้ตรงจุดเท่านั้น
การกำหนดปัญหาของทีม Data ที่นี่มี 2 แบบค่ะ
- ทีมทาง Business เดินเข้ามาหาพร้อมปัญหา : ประโยคที่คุ้นหูมากๆคือ “พี่แก้วครับ ผมมีเรื่องจะปรึกษา” จากนั้นเราก็จะนั่งจับเข่าคุยกันถึงปัญหาของทาง Business และคิดหา Solution ว่าเราจะใช้ Data ไปช่วยซัพพอร์ตหรือแก้ปัญหาที่ Business เจออย่างไรได้บ้าง
- ทีม Data กำหนดปัญหากันเอง : พอเราทำงานร่วมกับหลายๆทีม เราก็เริ่มรู้ว่าแต่ละทีมต้องการอะไร บางทีเราก็เห็นช่องทางที่จะใช้ Data ที่มีอยู่หรือความรู้ทาง Data science ไปช่วย support ทีมอื่นได้ เราก็จะสร้างโปรเจคขึ้นมากันเองในทีมเลย หรือบางทีเราไปอ่านบทความเจอการทำโมเดลของที่อื่น แล้วอยากจะลองทำเองบ้างและคิดแล้วว่า Business ได้ประโยชน์ เราก็ทำของเราเองค่ะ
ส่วนสกิลที่ใช้ในขั้นตอนนี้คือ Business analysis ค่ะ คือเราต้องเข้าใจ Business requirement และกำหนด Solution จากข้อมูลที่เรามีอยู่ได้ค่ะ
Data Collection
การเก็บข้อมูลเป็นสิ่งที่เราทำเยอะมากในปีที่ผ่านมา ในตอนแรกเราใช้แค่ข้อมูลที่ทางทีม Tech เก็บมาให้อย่างเดียว แต่พอ Business เริ่มมีโจทย์ที่มากขึ้นและกว้างขึ้น เราก็พบว่าข้อมูลที่เรามีอยู่ไม่เพียงพอสำหรับการวิเคราะห์ … หรือข้อมูลที่เรามีอยู่มันผิด … หรือบางทีปล่อย feature ออกไปแล้วแต่ยังไม่ได้เก็บข้อมูลก็มี!
เราเลยต้องเวิร์คกับทีม Tech และ Product ในเรื่องกระบวนการในการเก็บข้อมูล (ที่นี่เรากันเรียกว่า Data tagging) ของทุก Feature ทั้งบนเว็บและแอป และกำหนด Standard ในการทำ Data tagging ใหม่เกือบทั้งหมดเลย

หลังจากนั้นเราก็มีข้อมูลที่คลีนขึ้นและปริมาณที่เยอะขึ้นมากพอที่จะตอบโจทย์ Business ได้เกือบทุกอย่างแล้วแหละ (มั้ง)
นอกจากนั้น บางทีเรามี Product ที่อยู่ในช่วง MVP หรือช่วงทดสอบซึ่งยังไม่มีระบบการเก็บข้อมูล ทาง Business เองจะใช้ Google Sheet หรือ Trello เก็บข้อมูลไว้ก่อน ทีม Data ก็ต้องเขียน script ไปดึงข้อมูลมาเก็บไว้ในถังข้อมูลเองอีกด้วย ดังนั้นพวกสกิล Web Scraping หรือดึงข้อมูลจาก API เราก็ต้องรู้นะ
Data Integration & Preparation
พอเรามีข้อมูลแล้ว เราก็จะเอาข้อมูลที่เรามีอยู่ทั้งหมด มาทำ ETL (Extract, Transform, Load)ให้ข้อมูลอยู่ในรูปแบบที่เราจะสามารถนำไปวิเคราะห์หรือ Visualize ต่อได้
ที่นี่เรามีข้อมูลหลายรูปแบบ ทั้งแบบที่เป็น Relational Database และ NoSQL ค่ะ เมื่อก่อนข้อมูลที่เราใช้จะเก็บอยู่ใน Relational Database เท่านั้น เราก็ใช้แค่ SQL ในการทำ ETL แต่พอไปถึงจุดหนึ่งที่ query มันนานมาก เราเลยเปลี่ยนการเก็บข้อมูลบางส่วนที่โตเร็วมากมาเก็บใน Data Lake แทน แล้วเราก็เปลี่ยนมาใช้ Spark ที่สามารถทำ ETL ได้ทั้ง Relational และ NoSQL ทำให้เรา integrate ข้อมูลจากหลายๆ Data source ได้ และ Spark ยังทำให้เรา query ได้เร็วขึ้นมากกว่า 10x เลยด้วย
อันนี้เราทำงานร่วมกันกับทีม Tech ค่ะ ต้องขอขอบคุณทีม Tech ที่มาช่วย Implement ตรงนี้ด้วยค่ะ
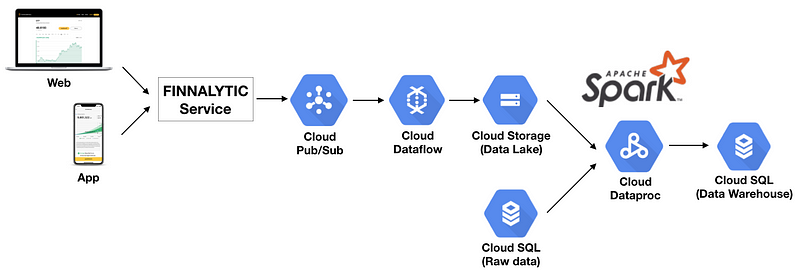
ส่วนสกิลที่ใช้ จากเมื่อก่อนที่เราใช้แค่ SQL ก็เพียงพอในการ process ข้อมูลแล้ว แต่พอได้มาทำตรงนี้เราคิดว่าแค่ SQL อาจจะไม่พอแล้ว ถ้าเราเล่นกับข้อมูลเยอะๆ เราจะต้องรู้พวก Big Data Solution อย่างพวก Spark และ Cloud Solution ด้วย อย่างที่นี่เองเราก็ใช้ Google Cloud ในการเก็บข้อมูลและทำ Data pipeline ค่ะ
2 ขั้นตอนที่ผ่านมามีความเป็น Engineer สูงมากค่ะ Data Scientist บางคนอาจจะไม่เจอนะ แต่เพราะบริษัทเราไม่มี Data Engineer เราเลยต้องมาทำเองจ้า T-T
Analysis & Modeling
ในที่สุด เราก็มาถึงส่วนที่ทุกคนคิดว่าเป็น Data Scientist กันจริงๆละ กว่าจะมาถึงตรงนี้ได้ เวลาเกือบทั้งหมดก็หมดไปกับขั้นตอนการเตรียมข้อมูลด้านบนหมดแล้วจ้าาาา
จะเห็นว่าเราเขียนว่า Analysis & Modeling เพราะไม่ใช่ว่าทุกงานเราจะใช้ Machine Learning มาทำโมเดลกันเสมอไปนะคะ
บางทีแค่ใช้ SQL ดึงข้อมูลมาสรุปผลทางสถิติง่ายๆ หรือบางปัญหาแค่ทำ Visualization ง่ายๆก็ตอบโจทย์ทาง Business ได้แล้วค่ะ
อีกอย่างคือด้วยความเป็น Startup เนี่ย Business เขาเอาเร็วค่ะ ถ้าจะทำโมเดลที่ได้วิเคราะห์เชิงลึกบางทีก็นานไปสำหรับเขา ต้องบอกว่าใจเย็นเย๊นนนนน ขอเวลาคิดขอเวลาทำแปร๊บบบบ
ในส่วนที่ว่าเอาข้อมูลไปวิเคราะห์อะไรบ้างเนี่ย เนื่องจากเราทำงานกับหลายทีมก็คือมีหลายอย่างมาก เลยขอยกตัวอย่างที่เราทำหลักๆกันค่ะ
- Customer Behavior : อันนี้เป็นงานหลักของทีมเราเลยค่ะ เพราะทุกทีมอยากรู้ว่าลูกค้าของเรามีพฤติกรรมแบบไหนบ้าง เช่น ใช้ Feature อะไรของเราบ้าง สนใจบทความไหนบ้าง พอเราได้พฤติกรรมมาแล้ว เราก็ใช้พวก Clustering มาทำ Customer Segmentation แบ่งประเภทลูกค้าได้ค่ะ

- Customer Journey : ดูว่าก่อนที่จะเป็นลูกค้าเรา ลูกค้าไปทำอะไรมาบ้าง ลูกค้า Drop-off ตรงไหน แล้วหา Golden Path ที่ทำให้ได้เราได้ลูกค้ามากที่สุด ตรงนี้ที่เคยใช้ก็จะมี Market Basket Analysis ดูว่า Action ไหนเกิดคู่กันแล้วเวิร์ค กับใช้ Sequence Pattern Mining คือดูเป็น path ยาวๆไปเลย
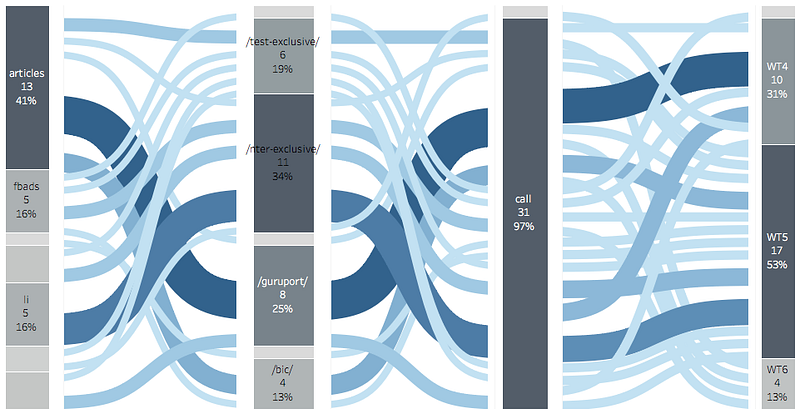
- Campaign Management : อันนี้น้องในทีมทำงานกับทีม Marketing อย่างใกล้ชิดเลยค่ะ ดูว่า Marketing ยิงแคมเปญไหนไป ยิงไปที่กลุ่มไหนได้ผล ใช้เงินเท่าไหร่ และได้ลูกค้าหรือ Conversion เท่าไหร่บ้าง
- Lead Scoring : ดูว่าคนไหนน่าจะเป็นลูกค้าเราได้บ้างจาก Behavior ของเขา อันนี้ใช้ ML มาทำเป็นำ Predictive Model เลยค่ะ
ที่ผ่านมาเรายังไม่เคยใช้ Deep Learning กับโมเดลทาง Business เลยค่ะ เพราะมันอธิบายที่มาที่ไปไม่ได้ แล้ว Business เขาก็จะถามว่าทำไมถึงเป็นแบบนู้น ทำไมถึงเป็นแบบนี้ ส่วนใหญ่ก็จะใช้ Logistic Regression กับตระกูล Tree ที่มันอธิบายได้ง่ายค่ะ
สกิลที่ใช้ตรงนี้ก็หนีไม่พ้นพวก Machine Learning Algorithm ต่างๆ และก็ภาษา R หรือ Python แต่ที่นี่เราใช้ Python กันเป็นภาษาหลักค่ะ
Presentation & Communication
อีกหนึ่งสกิลที่เราย้ำนักย้ำหนาว่าสำคัญมากๆ กับการเป็น Data Scientist คือการสื่อสารค่ะ
คือกว่าจะทำทำพวก Analytic & Modeling ออกมาได้ก็ว่ายากแล้ว แต่อธิบาย Data ให้เป็นภาษาคนให้ Business เข้าใจเนี่ยยากกว่า
ถึงข้อมูลจะเยอะและซับซ้อนมากแค่ไหน สุดท้ายเราต้องย่อยให้อยู่ในรูปแบบที่เข้าใจง่ายมากที่สุด สรุปประเด็นที่สำคัญที่ Business จะนำไปใช้ต่อได้ และเล่าเรื่อง (Storytelling) ให้ Business เข้าใจ Insight เราเจอ
ถ้าเราสื่อสารให้ Business เข้าใจไม่ได้ เขาจะตั้งคำถามกับสิ่งที่เราทำหรืออาจจะไม่เชื่อและมันจะมีผลกับ Change Management ในข้อถัดไปด้วยค่ะ
นอกจากสกิลการสื่อสารแล้ว ก็จะมีเรื่อง Data Visualization ที่เป็นการเลือกรูปแบบการนำเสนอข้อมูลให้เหมาะสมและเข้าใจง่าย ส่วน Tools ที่ใช้ทำ Report หรือ Dashboard ในการนำเสนอข้อมูลที่ควรจะใช้เป็นก็คือพวก Power BI หรือ Tableau (ที่นี่เราใช้ Tableau ค่ะ)
Action & Change Management
ส่วนนี้ไม่ค่อยมีคนพูดถึง แต่เราคิดว่าเป็นส่วนที่ทำให้งานของ Data Scientist มี Value มากที่สุดเลยล่ะ มันคือการที่เราทำงานออกมา สื่อสารไปให้ Business เข้าใจแล้ว ทาง Business เองสามารถตัดสินใจเปลี่ยนแปลงหรือพัฒนาบางอย่างให้ดีขึ้น
ซึ่งอันนี้ขึ้นอยู่กับ Mindset ของคนที่ทำงานด้วยนะ เราโชคดีที่คนในบริษัทนี้มี Mindset ที่เชื่อข้อมูลที่เราทำด้วย ทั้ง CEO, Co-founder เองก็เห็นความสำคัญของการใช้ข้อมูลมาตัดสินใจหลายๆอย่าง อย่างทีม Marketing, Product, Traction, UX/UI เวลาจะทำอะไรเขามักจะเข้ามาขอข้อมูลก่อนตัดสินใจ หรือพอเราเจออะไรที่มีปัญหาแล้ว alert ไปให้เขา เขาตัดสินใจเปลี่ยนแผนที่วางไว้เลยก็มี
อีกอย่างที่นี่ทีม Business ทุกทีมจะมี Dashboard ของทีมตัวเองค่ะ อยากได้ข้อมูลอะไรก็มาบอกทีม Data เราก็จะอัพเดทข้อมูลไว้ให้เอาไปมอนิเตอร์ วางแผนและตัดสินใจกันต่อไปค่ะ
ผลลัพธ์ของการทำโปรเจค Data Science จะ Success หรือ Fail ก็ขึ้นอยู่กับตรงนี้แหละ ถ้าทำงานเสร็จแล้วทำให้ Business เกิด Action หรือการเปลี่ยนแปลงในทางที่ดีขึ้น เราก็ถือว่าโปรเจคนั้น Success นะ
Model Deployment
ในกรณีที่มีการพัฒนาโมเดล หลังจาก Business โอเคกับโมเดลของเราแล้ว เราก็จะเอาโมเดลไปใช้จริงกัน ซึ่งจริงๆส่วนนี้จะเป็นส่วนของ Machine Learning Engineer
ต้องขอบอกก่อนว่า เรามีความรู้ในส่วนนี้น้อยมากๆ ตอนนี้โมเดลที่เราทำเป็นโมเดล ที่ใช้กันภายในบริษัทเป็นส่วนใหญ่ อัพเดตแค่วันละครั้ง ไม่ได้ต้องคำนวณเป็น Real-time เราเลยทำ Data pipeline และใช้ Cronjob อัพเดตโมเดลแบบง่ายๆค่ะ
ในส่วนที่ต้องการอัพเดตข้อมูลแบบ Real-time เราก็ใช้ Flask ค่ะ เพราะเราใช้ Python เป็นหลักอยู่แล้ว
ตอนนี้ก็กำลังศึกษาพวก Amazon SageMaker กับพวก Kubeflow อยู่ เผื่ออนาคตจะได้เอามาใช้ในกับ Application บนเว็บหรือแอปได้
จบแล้วค่ะ ประสบการณ์ 2+ ปีกับการทำ Data แบบ End-to-end ของเรา เราได้แตะทุกส่วนของการทำ Data ลองผิดลองถูกมาเยอะ แต่ก็ยังรู้สึกว่ายังมีเรื่องที่ยังไม่รู้อีกเยอะเลยค่ะ
เปิดรับคอมเม้น คำแนะนำ และอยากให้มีคนมาแชร์ประสบการณ์การทำ Data ด้วยกันค่ะ
Update May 2020

Leave a Reply